

这是一个创建于 86 天前的主题,其中的信息可能已经有所发展或是发生改变。
“如果我当年去问顾客他们想要什么,他们肯定会告诉我:一匹更快的马” -- 亨利•福特
前言
当我初入职场时,作为数据分析师的我,偶然体验到了网络爬虫( Web Crawler )自动化提取网页数据的能力,自此我一直对这个神奇的技术充满好奇。随着后来我不断钻研爬虫技术,逐渐了解到网络爬虫的核心技术,其中就包括网页解析( Parsing ),即通过分析网页 HTML 结构而构建基于 XPath 或 CSS Selector 数据提取规则的过程。这个过程长期以来都需要人工介入,虽然对于爬虫工程师来说相对简单,但如果需要大规模抓取,这个过程是非常消耗时间的,而且随着网页结构变化会增加爬虫维护成本。本篇文章将介绍我开发的基于大语言模型( LLM )的智能爬虫产品:Crawlab AI。虽然它还处于早期开发阶段,但已经展现出强大的潜力,有望让数据从业者轻松获取数据。
相关工作
作为爬虫管理平台 Crawlab 的创始人,一直都热衷于让数据获取变得简单和轻松。跟数据从业者不断交流,我意识到智能爬虫(或通用爬虫)的大量需求,即不用人工编写解析规则就可以抓取任何网站的目标数据。当然,也不止我一个人在研究和试图解决这个问题:2020 年 1 月,青南大佬发布了基于标点密度的通用文章解析库 GeneralNewsExtractor,可以 4 行代码实现通用新闻爬虫; 2020 年 7 月,崔庆才大佬发布了 GerapyAutoExtractor,基于 SVM 算法实现了列表页数据抓取; 2023 年 4 月,我通过高维度向量聚类算法,开发了 Webspot,同样可以自动提取列表页。这些开源软件的主要问题在于,识别的精准度与人工编写的爬虫规则有一定差距。
此外,商业爬虫软件 Diffbot 和 八爪鱼 通过自研的机器学习算法,也实现了部分通用数据抓取的功能。但可惜的是它们的使用成本相对较高。例如,Diffbot 的最低套餐就需要每月支付 299 美元的订阅费。
随着 2023 年大语言模型( LLM )的大爆发,智能爬虫研究似乎又找到新方向。ChatGPT 接入 Bing Search 之后,我们可以让其直接访问某个 URL 并根据内容提问。Builder.io 发布的 GPT-Crawler 可以全站抓取目标网站并接入 GPTs 。青南利用提示工程( Prompt Engineering )在 ChatGPT 中实现了通用爬虫,参考《一日一技:自动提取任意信息的通用爬虫》。
Crawlab AI
根据前人关于 LLM 在数据抓取方面的研究结果,我突然意识到 LLM 在或许不仅擅长处理文本,还可以处理更多非结构化数据,包括 HTML 。于是,我试着利用 LLM 去解析网页 HTML ,并根据要求提取出相应的数据,发现效果出人意料的好。LLM 不仅能准确提取出网页中的目标数据,而且能够将目标数据所在的节点路径通过 CSS Selector 提供出来。这样就可以让 LLM 根据 HTML 生成相应的提取规则,从而最终生成对应的爬虫代码。因此,利用 LLM 生成爬虫代码进行抓取的想法应运而生,我也根据这个思路发布了 Crawlab AI。目前 Crawlab AI 处于早期开发阶段,只提供一个网页让用户输入待解析网页的 URL ,然后自动解析出数据,并生成爬虫代码。

列表解析
首先,我们访问 https://ai.crawlab.io 。
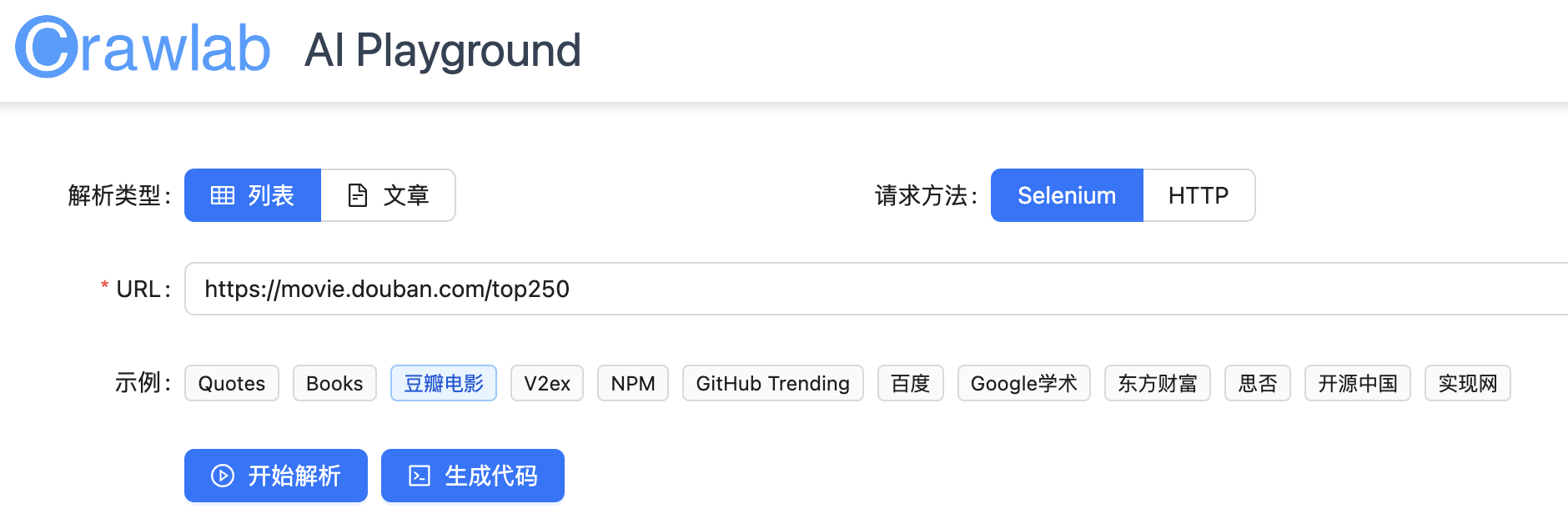
在这个页面,可以使用示例网页 URL ,也可以输入自定义的 URL 。这里我们选择示例中的 “豆瓣电影”,然后点击 开始解析。等待一会儿,就可以获得解析结果。
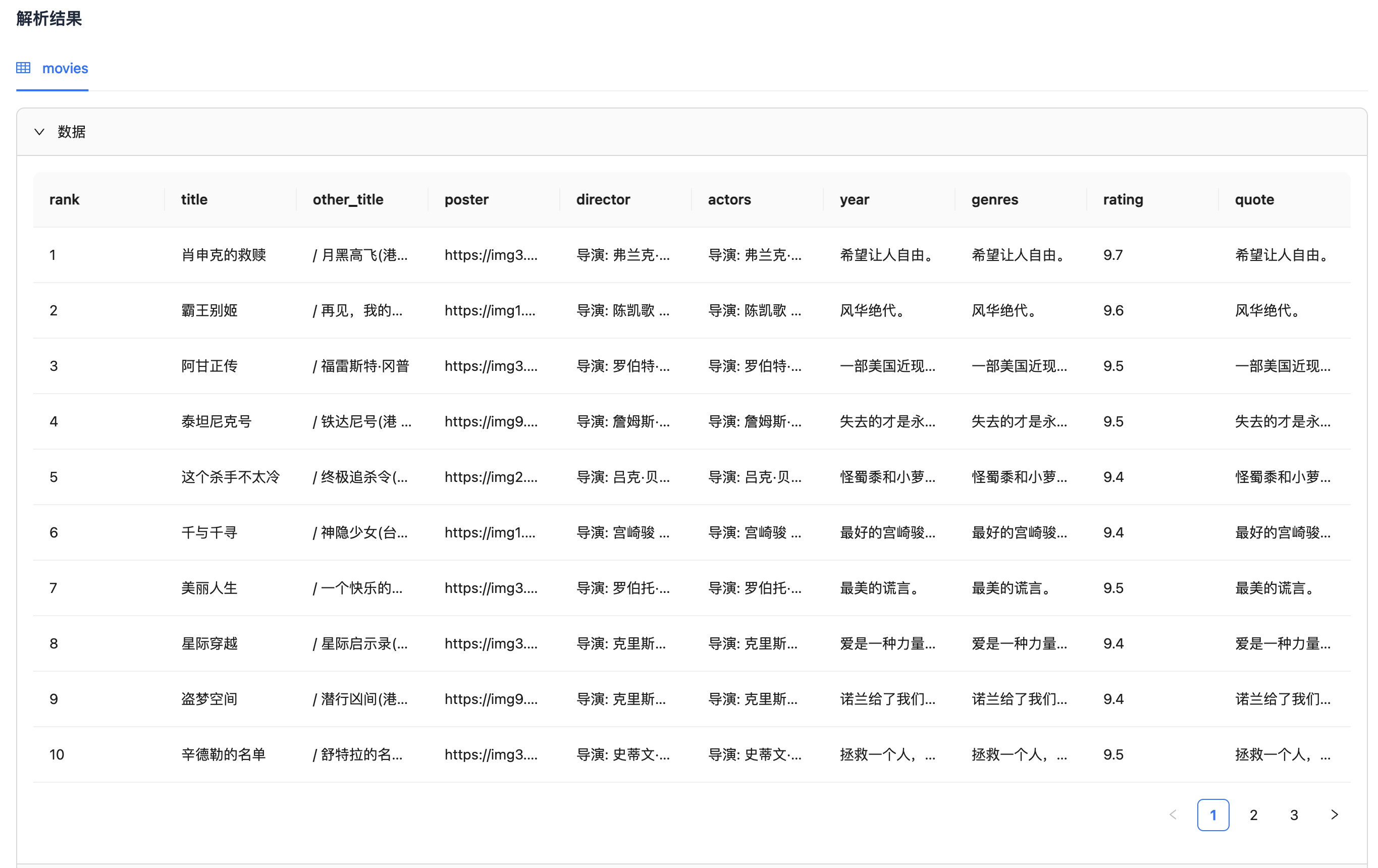
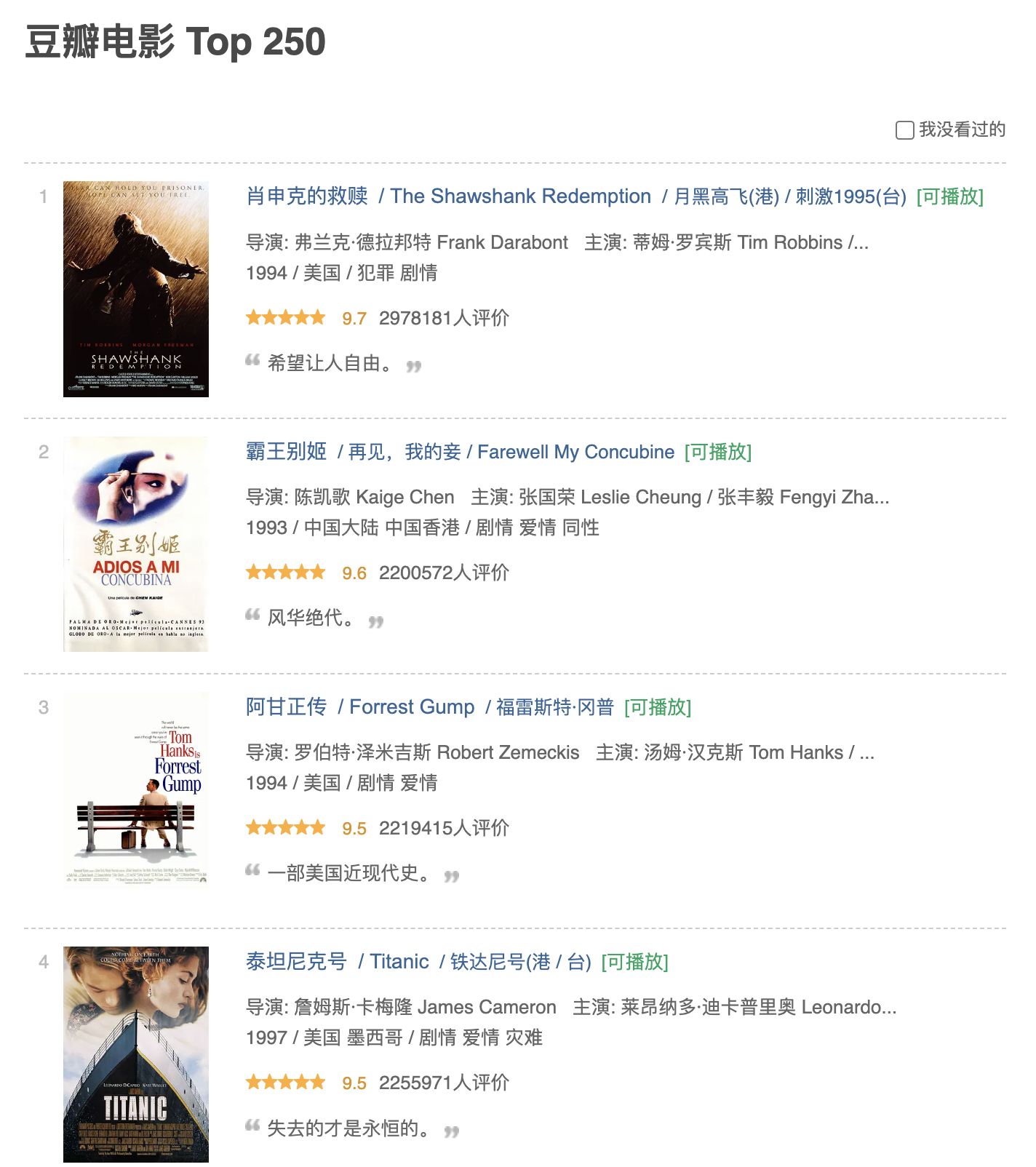
可以看到,豆瓣电影 Top 250 列表中各个字段的数据已经被提取出来,包括电影名、别名、导演、评分等。然后,我们对比一下原网页(如下),可以看到数据是一致的。
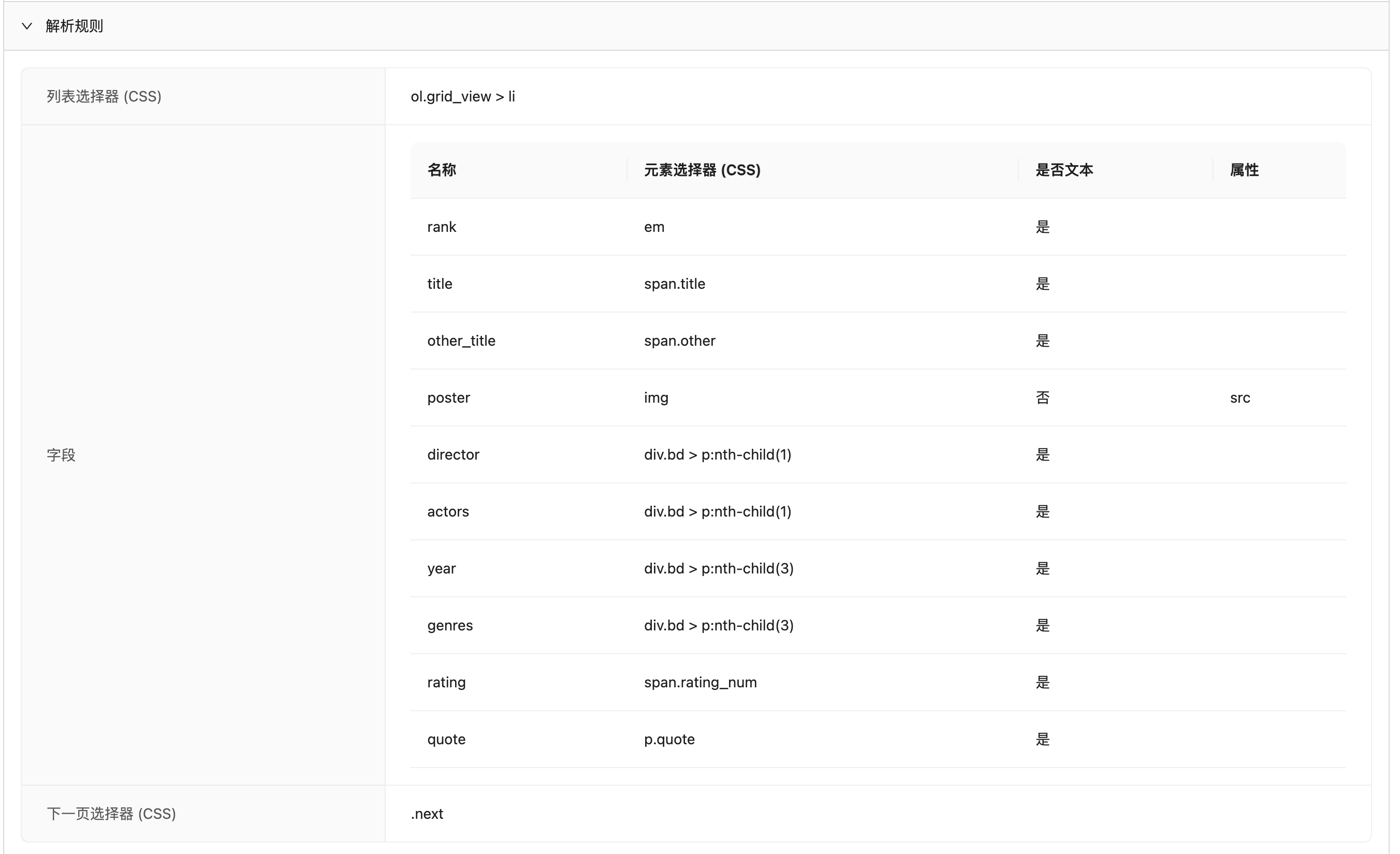
而且,不只是数据,Crawlab AI 还将解析规则,包括列表元素、字段、下一页的 CSS Selector ,都提取了出来,如下图。
现在,我们可以开始生成代码了,点击 生成代码,就可以弹框显示出豆瓣电影 Top 250 的爬虫代码了。
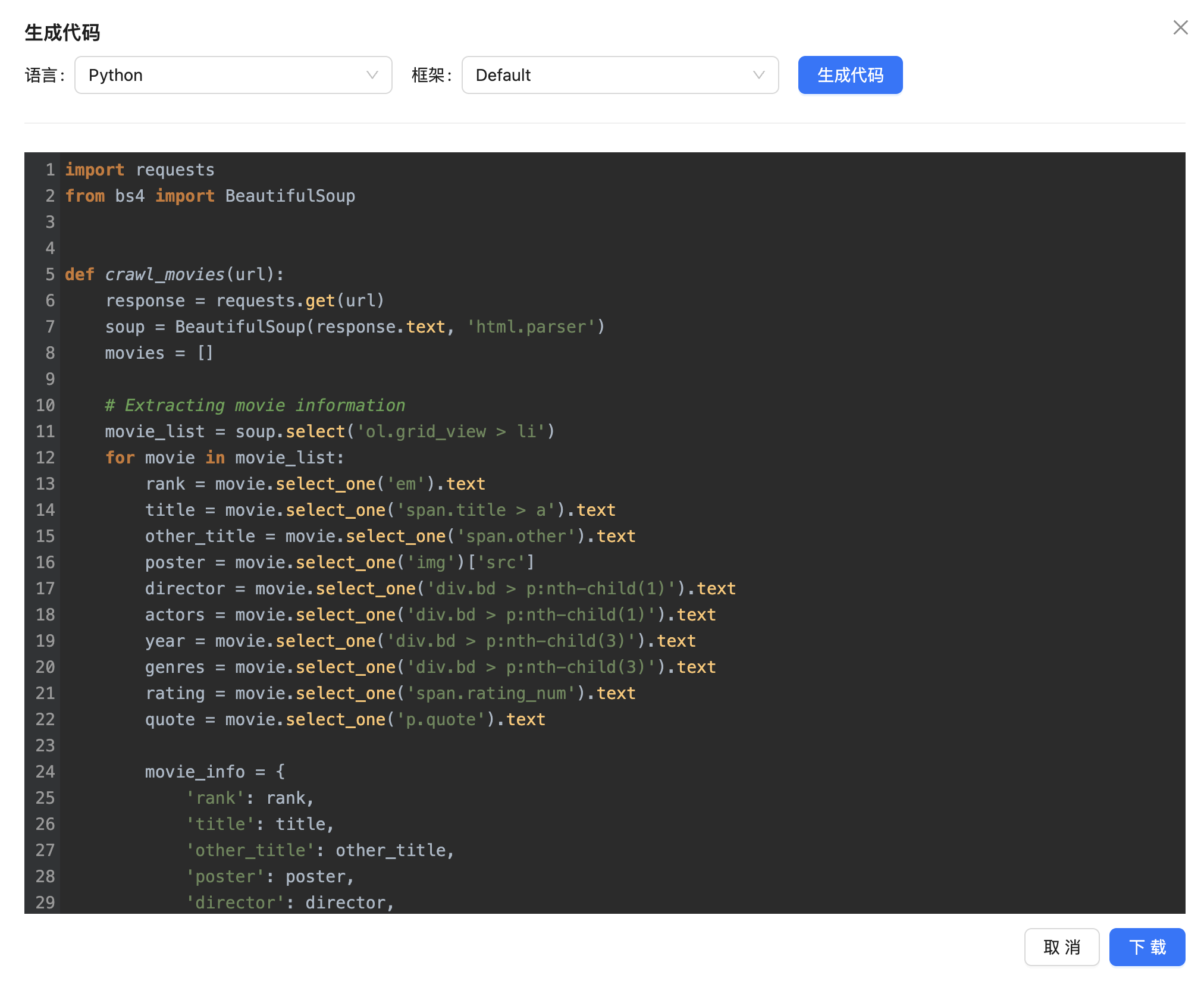
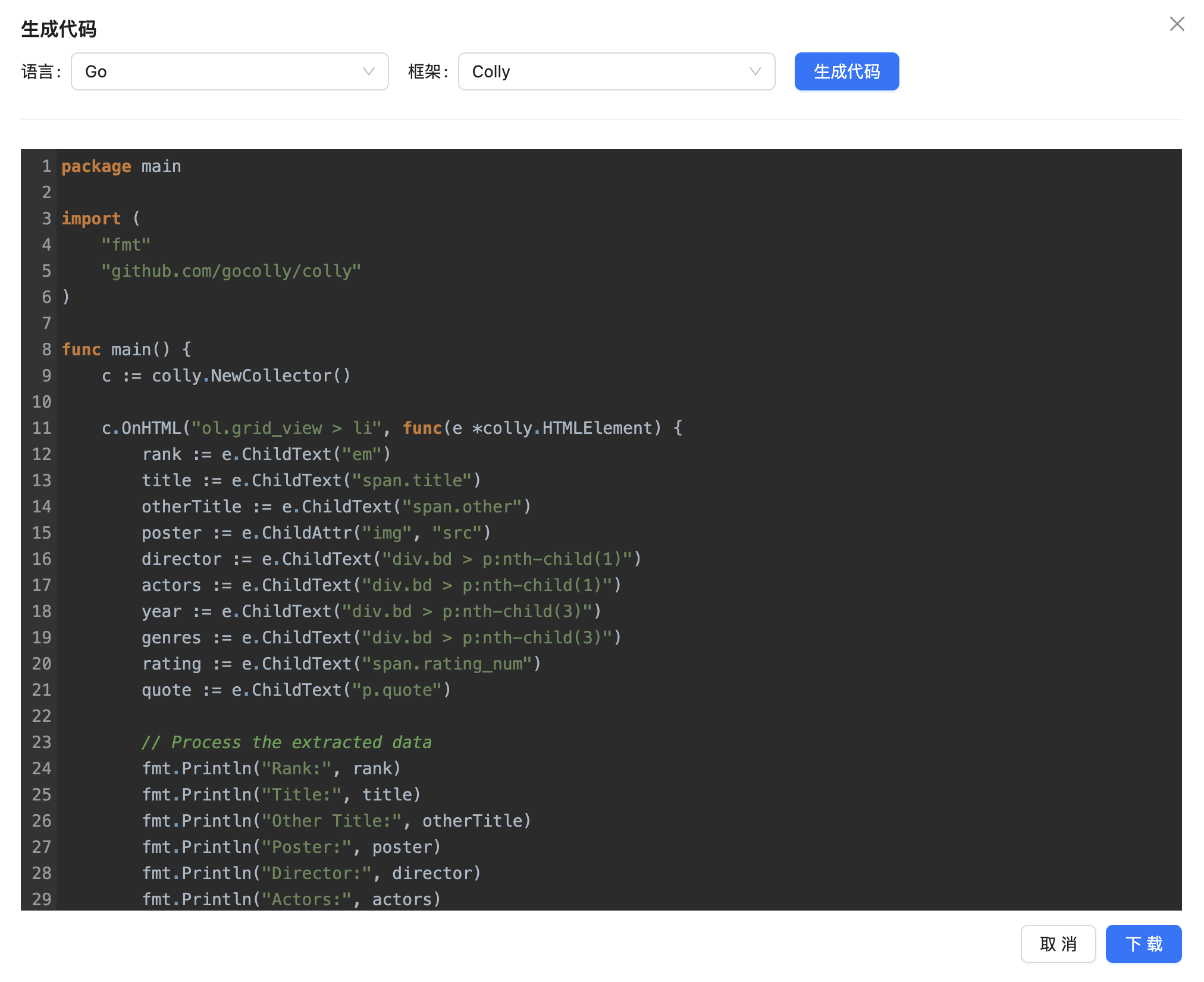
默认是 Python 代码,我们还可以选择 Node.js 、Go 等编程语言。我们还可以点击 下载 按钮将其下载下来。
文章解析
除了列表解析以外,Crawlab AI 还提供了文章解析功能,跟 GNE 等一样,也是可以提取文章正文的。这里我们试着解析一篇微信公众号文章,如下图。
然后,Crawlab AI 解析后的结果如下。

目前文章解析功能暂时不支持代码生成。未来会将这个功能加入进来。
未来计划
Crawlab AI 目前仅支持了 Web 界面,功能还比较基础。未来会加入更多实用的功能,包括批量解析、导入导出、集成 Crawlab 等。当然,目前的解析结果还达不到 100%,一些网站特别是复杂结构的网页无法完美解析,因此会进一步优化调校模型,来增强解析精准度。
总结
在本文中,我们深入探讨了智能爬虫在行业中的需求,回顾了智能爬虫技术的最新研究,并介绍了 Crawlab AI 这一创新的智能解析产品。尽管 Crawlab AI 目前还处于开发的初期阶段,仅提供了具有基本功能的 Playground ,它展示的解析效果已然令人印象深刻。用户无需编写任何代码,只需输入网站的 URL ,Crawlab AI 就能 自动生成解析规则,并提供 多种编程语言的爬虫代码。随着技术的持续进步和功能的不断增强,我们有理由相信,一个真正通用的智能爬虫解决方案正逐渐成为现实。
社区
如果您对笔者的文章感兴趣,可以加笔者微信 tikazyq1 并注明 "AI",笔者会将你拉入 "Crawlab AI" 交流群。
 |
1
lizhenda 85 天前
这篇文章有原文链接吗?
|
 |
3
QuinceyWu 85 天前 作为之前 Crawlab 深度使用者 顶一个
|
 |
7
bytebuff 85 天前
数据解析这块还是有发展方向的 类似 scrapy 官方: https://www.zyte.com/ 提供的智能解析 对于舆情类、新闻类等的数据解析应该是可行的
|
 |
8
tikazyq OP @bytebuff 确实,很多商用软件都已经比较成熟,Diffbot 这样的专注智能解析也很精准,我这个产品主要还是希望能降低数据获取的门槛,又兼顾开发者的自定义需求。例如,借助 LLM 生成爬虫代码,还可以自定义一些逻辑
|
 |
9
zoharSoul 85 天前
|
 |
11
mybro 85 天前 很好的思路👍
|
 |
13
xinshoushanglu 85 天前 支持
|
 |
14
rizon 85 天前
爬虫我只想解决反爬虫问题,有没有纯粹卖这种服务的,就是让我调用 api 完成一次页面数据的抓取。或者有啥其他搞点动态 IP 去请求服务的办法吗。
你像知乎这种的,我请求个三四次就开始触发验证了。哎。 |
|
15
rizon 85 天前
想咨询下 OP 啊,Crawlab AI 的在线服务支持反爬虫吗,是拥有大量 IP 来避免网站的反爬虫吗?
|
|
17
rizon 82 天前
有点好奇正文内容提取是怎么借助 AI 来做的,如果把一个页面的内容全部给 AI 来解析,token 数就太大了,消耗有些大。但是如果要缩短内容或者提取框架给 AI ,那又导致 AI 无法合理的判断正文区域。
这个事情真的很奇怪啊,难道真的只能全文提供给 AI ?感觉成本有些高啊。 |
|
18
tikazyq OP @rizon 你的怀疑没错,现在我的做法是将 html 分段传给 llm ,然后再用算法去筛选 llm 分析后的结果,最终返回出来。的确这样做的后果就是 token 数消耗可能过多,而且也有判断不准确的副作用。目前是用的 3.5 去测试的,所以准确率还不算特别高,后面会测试一下 gpt4 看看是否会解决。
|
