
这是一个创建于 778 天前的主题,其中的信息可能已经有所发展或是发生改变。
gen8 原来的系统是用鱼竿厂 720G 的,用了 3 年半挂了,折腾恢复系统花了不少功夫,尤其系统 ssd ,专门挑了个 5 年的 MX500 1T ,写入保 300TBW ,我想少是少点,我的系统压力不大,应该还好吧。
这才不到一个月健康度就只有 96%了!!!
写了个脚本,每 10 分钟读 246 Total_LBAs_Written ,如下
659,38580902742
659,38591520774
659,38602126046
659,38612742718
659,38623395998
659,38634006542
660,38644633990
660,38655273190
660,38665916366
第一列是开机小时数,第二列是 Total_LBAs_Written ,每个 LBA 512 字节,几乎每 10 分钟写入
10000000*512/1024/1024=4.8G ,每分钟 500M
我这系统就虚拟一个黑裙 4G 内存,一个 ubuntu server6G 内存,宿主系统还剩 6G ,三个系统 swap 基本都是没用。
怎么会这么大写入?是不是算的公式有问题。
黑裙 PT 挂了 10 个种子,大部分时间都无流量,还有个 surveillance station 管一个摄像头,但是用的 265 ,码率才 100k ,而且存在另外的 HDD 上。
这才不到一个月健康度就只有 96%了!!!
写了个脚本,每 10 分钟读 246 Total_LBAs_Written ,如下
659,38580902742
659,38591520774
659,38602126046
659,38612742718
659,38623395998
659,38634006542
660,38644633990
660,38655273190
660,38665916366
第一列是开机小时数,第二列是 Total_LBAs_Written ,每个 LBA 512 字节,几乎每 10 分钟写入
10000000*512/1024/1024=4.8G ,每分钟 500M
我这系统就虚拟一个黑裙 4G 内存,一个 ubuntu server6G 内存,宿主系统还剩 6G ,三个系统 swap 基本都是没用。
怎么会这么大写入?是不是算的公式有问题。
黑裙 PT 挂了 10 个种子,大部分时间都无流量,还有个 surveillance station 管一个摄像头,但是用的 265 ,码率才 100k ,而且存在另外的 HDD 上。
第 1 条附言 · 2022-09-16 11:07:35 +08:00
查了两天,是群晖虚拟机里一个定时任务引起的。这个任务是一个检查 ngrok 客户端有没有挂掉的脚本,每分钟启动一次,原来这个脚本一跑就增加 300M 写入。用了个 numerize 包,但是本来应该是 G 的位置,都用 B 表示了
start from 2022-09-15 00:10:01,length: 600 seconds,total write 234.83B,write 3.86BB in this section,speed 6.44MB/s
start from 2022-09-15 00:20:01,length: 600 seconds,total write 238.45B,write 3.62BB in this section,speed 6.04MB/s
start from 2022-09-15 00:30:01,length: 600 seconds,total write 242.08B,write 3.62BB in this section,speed 6.04MB/s
解决也很奇怪,这个脚本原来是放在 hdd 上的,移到群晖的 ssd 的系统目录 volume1 里,然后直接在 corntab 里加了一行,没有用群晖的计划任务添加,就好了。
start from 2022-09-16 09:30:01,length: 600 seconds,total write 657.88B,write 35.39MB in this section,speed 58.98KB/s
start from 2022-09-16 09:40:01,length: 600 seconds,total write 657.94B,write 59.24MB in this section,speed 98.73KB/s
start from 2022-09-16 09:50:01,length: 600 seconds,total write 657.97B,write 30.7MB in this section,speed 51.17KB/s
start from 2022-09-15 00:10:01,length: 600 seconds,total write 234.83B,write 3.86BB in this section,speed 6.44MB/s
start from 2022-09-15 00:20:01,length: 600 seconds,total write 238.45B,write 3.62BB in this section,speed 6.04MB/s
start from 2022-09-15 00:30:01,length: 600 seconds,total write 242.08B,write 3.62BB in this section,speed 6.04MB/s
解决也很奇怪,这个脚本原来是放在 hdd 上的,移到群晖的 ssd 的系统目录 volume1 里,然后直接在 corntab 里加了一行,没有用群晖的计划任务添加,就好了。
start from 2022-09-16 09:30:01,length: 600 seconds,total write 657.88B,write 35.39MB in this section,speed 58.98KB/s
start from 2022-09-16 09:40:01,length: 600 seconds,total write 657.94B,write 59.24MB in this section,speed 98.73KB/s
start from 2022-09-16 09:50:01,length: 600 seconds,total write 657.97B,write 30.7MB in this section,speed 51.17KB/s
第 2 条附言 · 2022-10-04 11:07:16 +08:00
写了个脚本,监控ssd用量
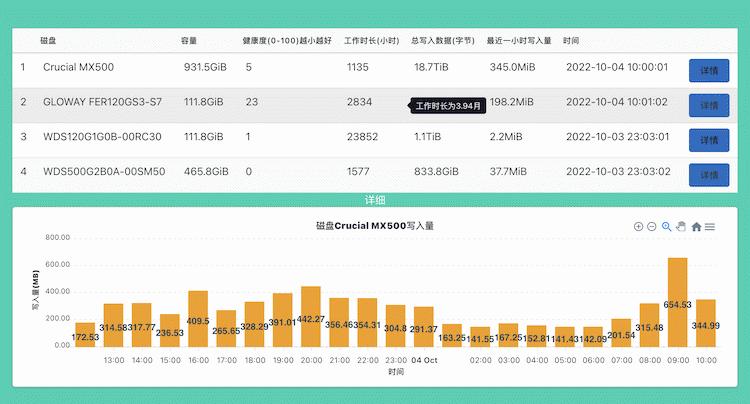
第 3 条附言 · 2022-10-04 11:24:29 +08:00

