
容器监控:这些高级的 Docker Metrics 你不能错过
daocloud · DaoCloud · 2016-08-17 15:10:57 +08:00 · 546 次点击这是一个创建于 3056 天前的主题,其中的信息可能已经有所发展或是发生改变。
文 | 斯蒂凡·蒂斯
本文由 DaoCloud 独家翻译
翻墙点击 原文链接
监控 Docker 环境是一项有挑战性的工作。为什么呢?因为一般情况下,每个容器运行单一的进程,拥有自己的环境,使用虚拟网络,或者以多种方式管理存储。
一方面,传统的监控方法是从其所运行的各个服务器和应用中调取度量。这些服务器与运行这些服务器上的应用通常都很稳定,正常运行时间也非常长。 Docker 的部署是不同的:多个容器可能运行很多应用,共享一个或多个底层主机的资源。对运行 Docker 的服务器来说,运行上千个短期容器(比如跑批量工作的容器)的同时,还运行着一些持久的服务,这些并不是什么怪事。传统监控工具无法适应如此复杂的工作环境,因此不适合用于这样的部署方式。
另一方面,一些新式监控方法(比如源自 Sematext 的 SPM )则在设计之初就整合了这类复杂的系统,甚至还能对 Docker 监控生成报告。而且,容器资源共享需要对资源使用限制提出更严格的要求,这是另一个你必须仔细考虑的问题。要对资源配量做出合理的判断,你需要清楚地知道容器达到了哪些极限,或者造成了哪些错误。我们建议,根据定义的限制来设置警报;这样做,你甚至能在错误浮现出来之前,就判断好限制或资源使用情况。
Docker 容器 != 虚拟机或服务器
扔掉你老掉牙的旧式监控吧, Docker 专用监控用起来
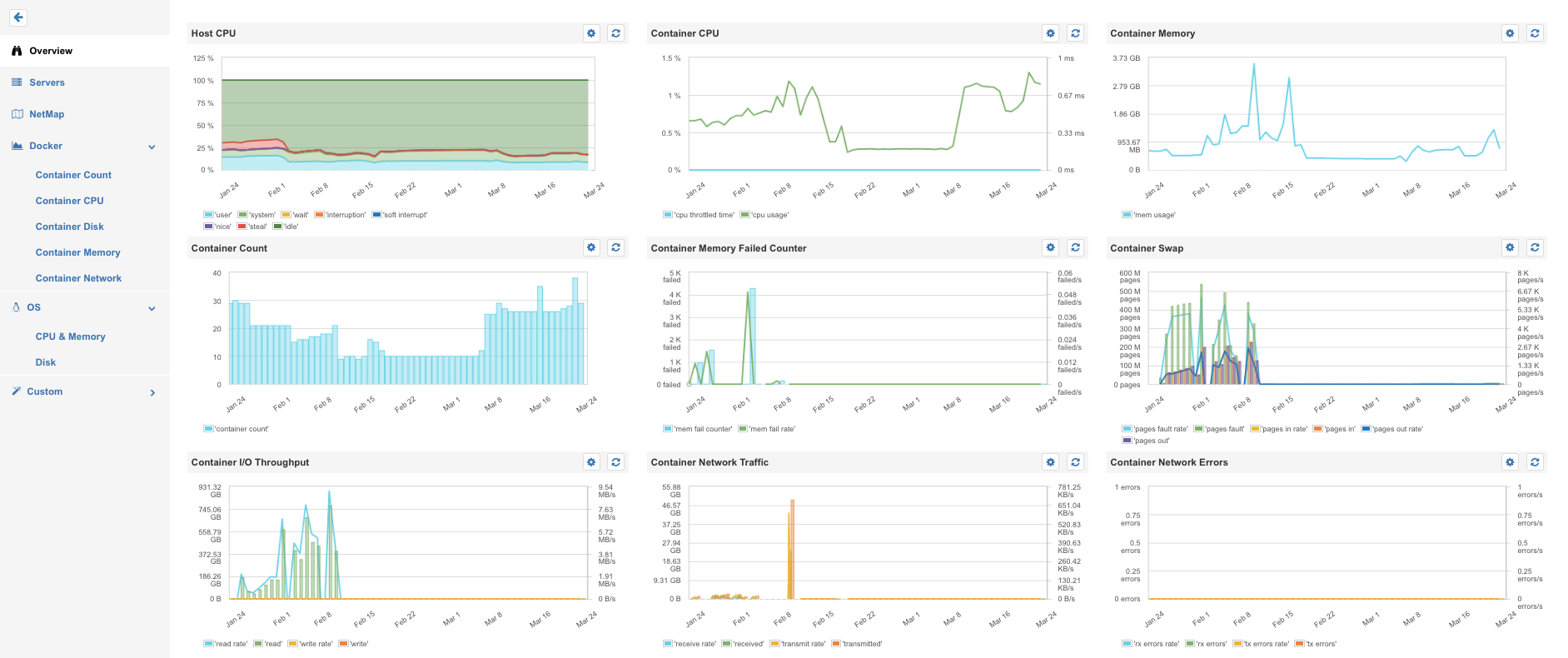
看看你 Docker 主机的资源
主 CPU
了解主机和容器的 CPU 使用状况,能帮助你最大化利用 Docker 的主机资源。容器 CPU 可以人为调低使用率,来防止一个高负荷的容器占用了所有可用的 CPU 资源,拖慢了其他容器的速度。调低 CPU 时间,可以有效确保必要的服务能够获得最低限度的进程资源——就像 Unix/Linux 里经典做法一样。
当资源利用被最大化, CPU 的高效利用就指日可待了。警报也不需要设置得很频繁,只要在 CPU 利用率下降(服务器故障),或增长得超过一定最大极值(比如 85%)时触发警报就可以了。
一台使用过度的 Docker 主机是麻烦的征兆
一台使用不足的主机是你浪费钱败家的征兆
主机内存
要了解当前的操作和工作计划,各个 Docker 主机使用的总内存是很重要的。 Docker Swarm 这类的动态集群管理器会用主机上可用的内存和容器的所需内存,来决定最好在哪台主机上启动新容器。如果集群管理器无法找到一个有足够资源供应容器的主机,那么部署就可能失败。这也就是为什么,了解主机内存使用情况和容器的内存极限是非常重要的。根据 Docker 应用的足迹,调整新集群节点的容量,有助于最大化资源的利用率。
不, Linux 不吃你的内存
不过在缓冲的/缓存的 memory 为零时,就需要拓展现有的集群了
主机硬盘空间
Docker 镜像和容器会消耗额外的硬盘空间。比如,一个应用镜像可能包括一个 Linux 操作系统,并根据容器内基本的镜像大小和安装工具的大小,占用空间从 150MB 到 700MB 不等。持久化的 Docker volumes 也会消耗主机硬盘空间。根据我们的经验,留意硬盘空间,适当使用清理工具,对于 Docker 主机的持续工作是很必要的。
好孩子会清理他们的房间
好的 Docker 使用者会清理硬盘中用不上的容器和镜像
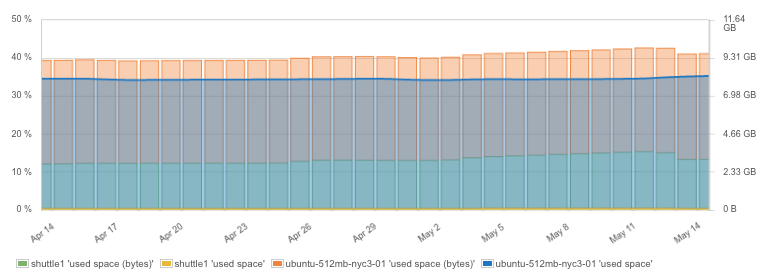 Docker 主机上的硬盘空间使用
Docker 主机上的硬盘空间使用
由于硬盘空间十分重要,对硬盘空间使用设置相应的警报,发出及时的预警,留出足够的时间来清理硬盘或添加额外的 volumes ,就显得很有必要。举个例子, SPM 会自动为你设置硬盘空间使用的警报规则,所以你就不用劳心去弄了。
经常删掉不用的容器和镜像,清理硬盘,养成良好的操作习惯。
运行中的容器总数
出于很多原因,当前和过往的容器数目是一项有趣的度量。比方说,在部署和升级的过程中,确保所有东西都运行如旧,是非常方便的。
当 Docker Swarm 、 Mesos 、 Kubernates 、 CoreOS/Fleet 这类集群管理器自动安排容器用不同的部署策略运行在不同的主机上时,各个主机上运行的容器数量能帮助你验证已激活的部署策略。一张条形图可以展示各个主机上容器的数量和总的容器数,提供了一个快速、可视化的方式,呈现集群管理器是如何在所有可用主机上部署容器的。
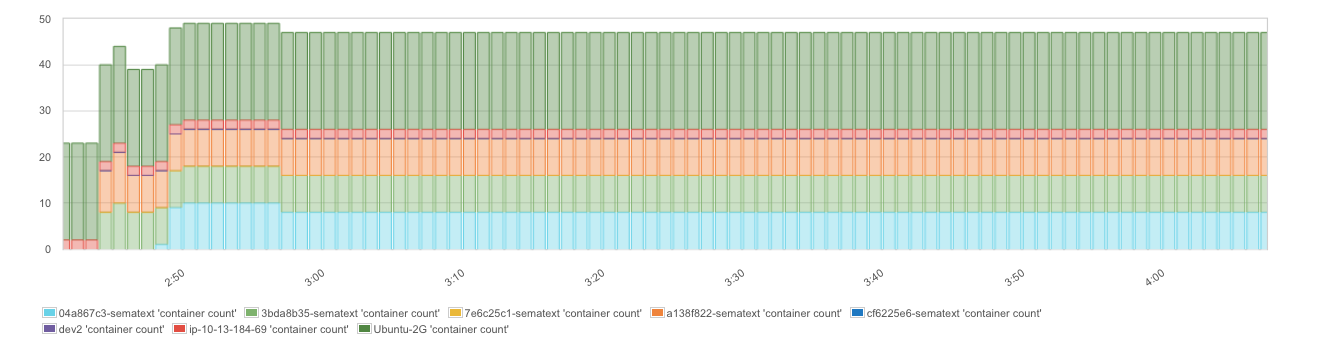 容器会随着时间推移,统计各个 Docker 主机
容器会随着时间推移,统计各个 Docker 主机
用异常检测而非基于阀值的监控方法,来找到那些会造成麻烦的突发容器位移
这一度量可以根据使用情况采取不同的“模式”。比方说,容器中运行的批量任务和长期服务通常会导致不同的容器统计模式。一个批量任务通常按命令启动容器,或者定时启动容器,而执行这一任务的容器会在相当短的时间内结束。在这一方案里,容器的数量会产生极大的变动,把容器统计度量变得很“浮夸”。另一方面,网络服务端或数据库等长期服务通常会运行到软件升级时被重新部署为止。尽管收缩机制可能会依据负载、运输和其他因素来增加或减少容器的数量,但容器统计度量一般会相当稳定,因为在这些情况下,容器会更平缓地增添和移除。由此,对于运行中的容器数量,我们并没有一个通用的模式来设置默认的 Docker 警报规则。
另外,基于异常检测的警报主要探测短期窗口内容器总数(或特定主机内容器数量)的突然变化,这对于日常使用来说是一项极大的便利。简易的基于阀值的监控方法只有在已知最大值和最小值的情况下才管用,而在瞬息万变的环境里,外部因素时常影响规模的涨缩,因此这种方法经常没有用武之地。
容器度量
容器度量和每个 Linux 进程里的可用度量基本一致,但还包括了 Docker 用 cgroups 设定的极限,例如 CPU 或内存的使用极限。请注意,像 Docker 专用 SPM 这类复杂的监控解决方案,可以整合不同层面上(如 Docker 主机 /集群节点、图像名称或 ID ,以及容器名称或 ID )的容器度量。拥有此般神功,跟踪主机的资源使用情况,应用类型(图像名称)或特定的容器将变得非常容易。在接下来的例子中我们会用到不同层面的整合。
用现代的 Docker 监控解决方案对主机、节点、镜像或容器大卸八块
你会需要这个
容器 CPU ——减弱 CPU 时间
最基本的信息之一,就是 CPU 目前被所有容器、镜像或特定的容器占用了多少。用 Docker 的一大优势就是能通过容器限制对 CPU 的占用。当然,如果你不做好测量,就无法协调并实现最大化,所以监测这些限制就是先决条件。观察一个容器 CPU 使用量的减弱时间,能为你判断 Docker 内 CPU 份额的设定提供必要的信息。请注意,只有当主机 CPU 使用量越过最大值时, CPU 时间才会减弱。只要主机还有剩余的 CPU 线程能供 Docker 使用,她就不会减弱 CPU 的占用。因此,一般情况下 CPU 是不会减弱的,任何一点这样的度量出现,通常都意味着一个或多个容器需要主机提供更多的 CPU 支持。
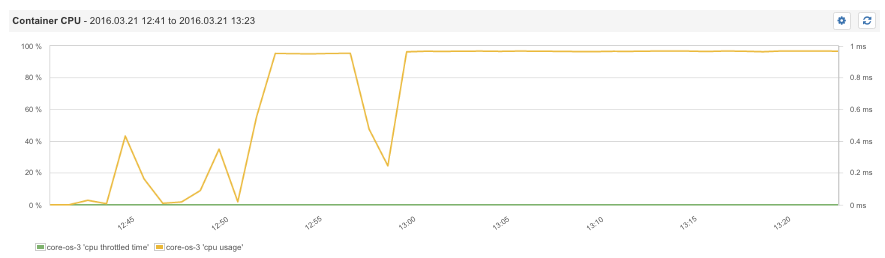 容器 CPU 使用情况和减弱的 CPU 时间
容器 CPU 使用情况和减弱的 CPU 时间
接下来这张截屏展示了占用了 5% CPU 的容器正使用 "docker run -cpu-quota=5000 nginx" 命令,我们清楚地看到 CPU 是 如何在 Docker 擎的驱动下逐渐减弱到 5% 左右的。
 容器 CPU 使用情况和 CPU 减弱时间(减至 5%)
容器 CPU 使用情况和 CPU 减弱时间(减至 5%)
容器内存——故障计数器
给容器设置内存限制是有好处的,这样可以避免某个耗费内存的容器一口气吃光所有能用的内存,害得同一服务器内的其他容器都没内存可用。在 Docker 运行命令中,资源的运行时间限制是可以被定义的。举个例子,"-m 300M" 意为给容器的内存设置了 300MB 的上限。 Docker 设置了一个度量,名叫容器内存故障计数器。每一次内存分配失败了——也就是,每一次预置的内存限制被突破——计数器就会往上计数。因此,这个度量意味着一个或多个容器需要分配更多的内存。如果容器内的进程因故终止,我们也能从 Docker 看到内存的事件。
Docker 内存故障计数器告诉你容器什么时候需要更多的内存
警报是您的好友
内存故障计数器发出讯息,是一件很严重的事件,在内存故障计数器上安放警报,能有效检测到内存限制的错误设置,或发现试图超量占用内存的容器。
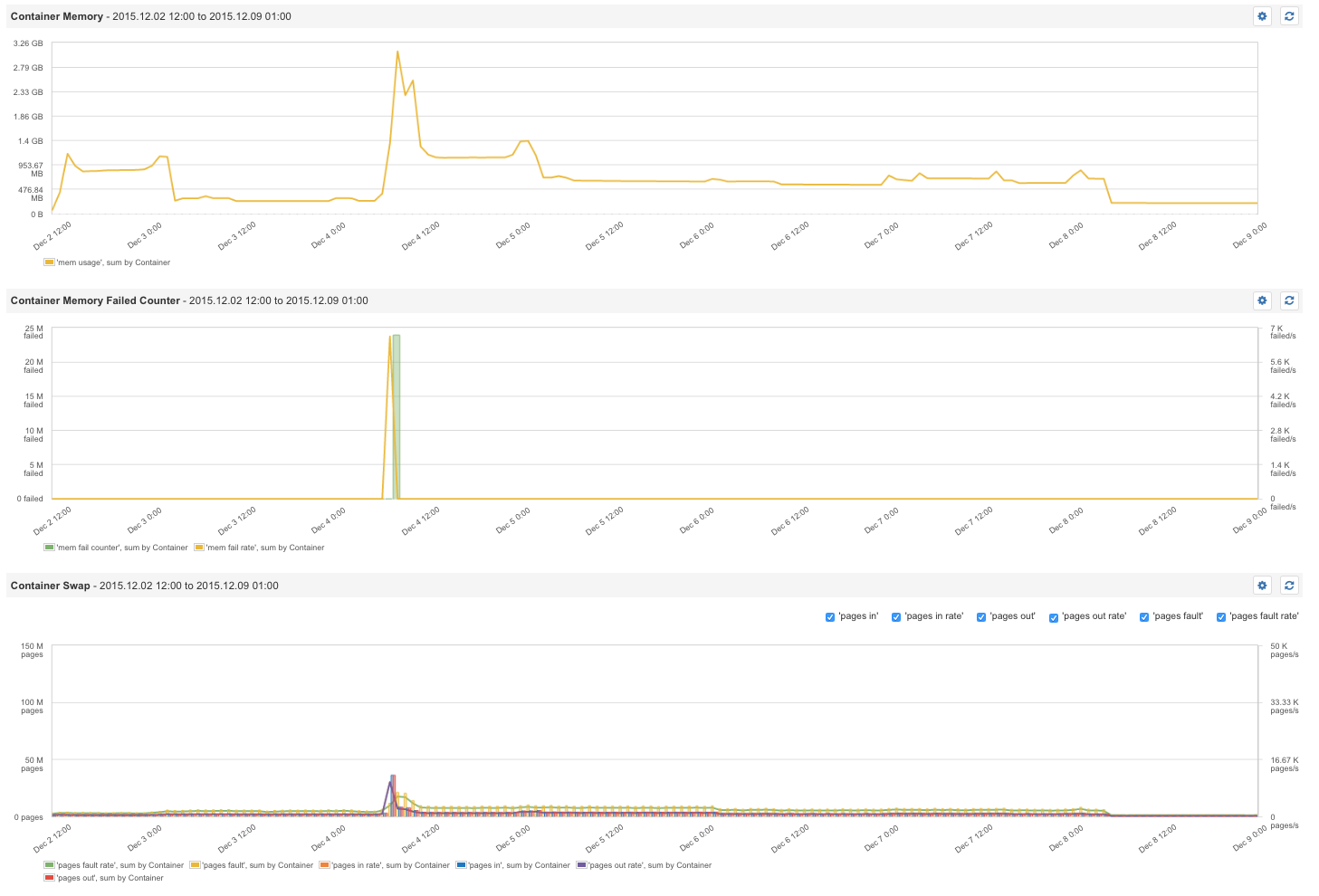 容器内存使用情况
不同应用有不同的内存足迹。要创建一个稳定的环境,了解应用容器的内存足迹是很重要的。容器内存限制确保了各个应用都能良好运行,不会占用过多内存,避免了同一主机内容器间的互相影响。最好的做法是在一些循环内协调好内存设定:
容器内存使用情况
不同应用有不同的内存足迹。要创建一个稳定的环境,了解应用容器的内存足迹是很重要的。容器内存限制确保了各个应用都能良好运行,不会占用过多内存,避免了同一主机内容器间的互相影响。最好的做法是在一些循环内协调好内存设定:
- 监控应用容器的内存使用情况
- 根据观察结果设定内存限制
- 继续监控内存、内存故障计数器和内存外事件。如果内存外事件发生了,容器的内存就可能需要调高,或者需要进行排故,来找到内存高消耗的原因。
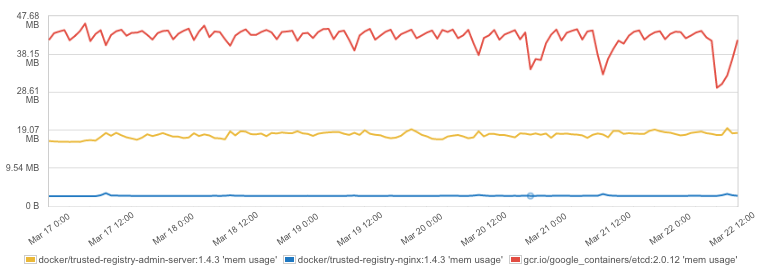 Docker 容器内存使用状况
Docker 容器内存使用状况
交换容器
就像其他进程的内存一样,容器内存是可以和硬盘交换的。对于 Elasticsearch 或 Solr 这样的应用,你总能这样那样地找到在 Linux 主机上解除交换的办法——但如果你在 Docker 上运行这类应用,仅仅在 Docker 运行命令中设置 "-memory-swap=-1" 就足够了。
不想看到你的容器交换?
在 Docker 运行命令中用这条吧:“ -memory-swap=-1 ”。事情搞定!
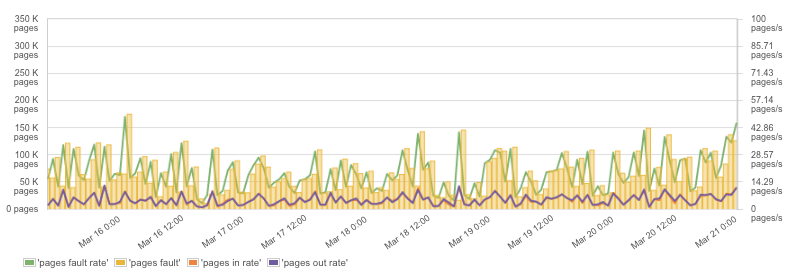 容器交换,内存页面,和交换率
容器交换,内存页面,和交换率
容器磁盘 I / O
在 Docker 中,多个应用并发地使用相同的资源。因此,观察磁盘 I / O 能帮助你为特定的应用定义限制,并给数据存储或网络服务端等关键应用分配更高的吞吐量,同时还为批量操作减弱磁盘 I / O 。比如,“-it -device-write-bps/dev/sda:1mb mybatchjob ” 这条 Docker 命令,可以把容器硬盘的最高读取速度设定为 1MB/s 。
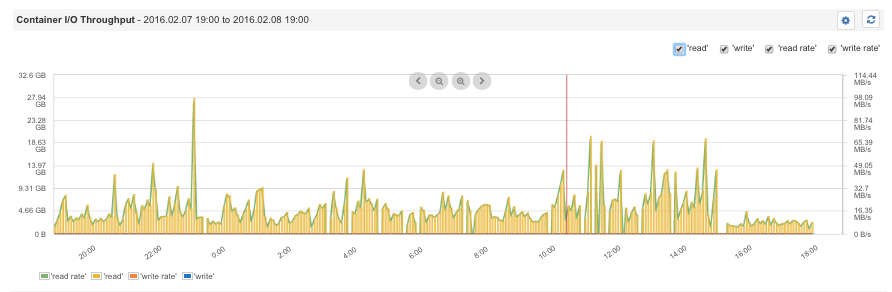 容器 I / O 吞吐量
容器 I / O 吞吐量
防止某个 Docker 容器吃光你的磁盘 I / O
举例:使用 “-device-write-bps /dev/sda:1mb ” 命令
容器网络度量
容器网络是很有挑战性的。默认中,所有容器共享一个网络,或者容器会被连在一起,在同一主机内共享一个局域网。不过,如果要给不同主机上的容器连上网,就需要一个覆盖式网络了,要么就让容器共享主机的网络。网络配置有很多可选项,这也就意味着网络故障也会有很多可能的原因。
此外,需要重点照看的可不止各种故障和丢失的数据包 。如今,绝大多数应用都仅仅依靠网络通讯。尤其对负载均衡器这类容器而言,虚拟网络的吞吐量是个很大的瓶颈。还有,网络交通可能是一个好的指示器,可以告诉你有多少应用正在被客户使用,有时你还会看见高峰,这说明客户端应用里出现了一系列服务冲突,负载测试或者一个故障。所以请紧盯网络交通——在很多情况下这是个很有用的度量。
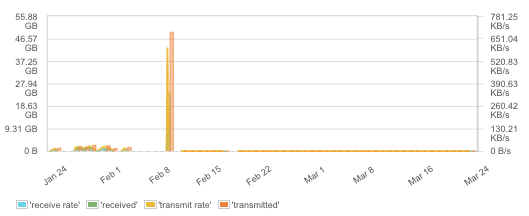 网络交通和传输率
网络交通和传输率
总结
这些就是了——需要关注的高级 Docker 度量。持续留意这些高级度量,并辅以相应的分析,能帮助你四平八稳地完成各个平台上的 Docker 部署——诸如 Docker Swarm 、 Docker 云、 Docker 数据中心或任何其他支持 Docker 容器的平台。如果你你想了解更多有关 Docker 监控和存入的知识,请登录 ematext.com/blog 或关注 @sematext 。
注意:本文中的所有图片均源自 Sematext 的 SPM 性能监控工具及其 Docker 监控集合
目前尚无回复