
这是一个创建于 2037 天前的主题,其中的信息可能已经有所发展或是发生改变。
本系列将利用阿里云容器服务,帮助您上手 Kubeflow Pipelines.
介绍
机器学习的工程复杂度,除了来自于常见的软件开发问题外,还和机器学习数据驱动的特点相关。而这就带来了其工作流程链路更长,数据版本失控,实验难以跟踪、结果难以重现,模型迭代成本巨大等一系列问题。为了解决这些机器学习固有的问题,很多企业构建了内部机器学习平台来管理机器学习生命周期,其中最有名的是 Google 的 Tensorflow Extended,Facebook 的 FBLearner Flow,Uber 的 Michelangelo,遗憾的是这些平台都需要绑定在公司内部的基础设施之上,无法彻底开源。而这些机器学习平台的骨架就是机器学习工作流系统,它可以让数据科学家灵活定义自己的机器学习流水线,重用已有的数据处理和模型训练能力,进而更好的管理机器学习生命周期。
谈到机器学习工作流平台,Google 的工程经验非常丰富,它的 TensorFlow Extended 机器学习平台支撑了 Google 的搜索,翻译,视频等核心业务;更重要的是其对机器学习领域工程效率问题的理解深刻,Google 的 Kubeflow 团队于 2018 年底开源了 Kubeflow Pipelines(KFP), KFP 的设计与 Google 内部机器学习平台 TensorFlow Extended 一脉相承,唯一的区别是 KFP 运行在 Kubernetes 的平台上,TFX 是运行在 Borg 之上的。
什么是 Kubeflow Pipelines
Kubeflow Pipelines 平台包括:
- 能够运行和追踪实验的管理控制台
- 能够执行多个机器学习步骤的工作流引擎 ( Argo )
- 用来自定义工作流的 SDK,目前只支持 Python
而 Kubeflow Pipelines 的目标在于:
- 端到端的任务编排: 支持编排和组织复杂的机器学习工作流,该工作流可以被直接触发,定时触发,也可以由事件触发,甚至可以实现由数据的变化触发;
- 简单的实验管理: 帮助数据科学家尝试众多的想法和框架,以及管理各种试验。并实现从实验到生产的轻松过渡;
- 通过组件化方便重用: 通过重用 Pipelines 和组件快速创建端到端解决方案,无需每次从 0 开始的重新构建。
在阿里云上运行 Kubeflow Pipelines
看到 Kubeflow Piplines 的能力,大家是不是都摩拳擦掌,想一睹为快?但是目前国内想使用 Kubeflow Pipeline 有两个挑战:
- Pipelines 需要通过 Kubeflow 部署;而 Kubeflow 默认组件过多,同时通过 Ksonnet 部署 Kubeflow 也是很复杂的事情;
- Pipelines 本身和谷歌云平台有深度耦合,无法运行在其他云平台上或者裸金属服务器的环境。
为了方便国内的用户安装 Kubeflow Pipelines,阿里云容器服务团队提供了基于 Kustomize 的 Kubeflow Pipelines 部署方案。和普通的 Kubeflow 基础服务不同,Kubeflow Pipelines 需要依赖于 mysql 和 minio 这些有状态服务,也就需要考虑如何持久化和备份数据。在本例子中,我们借助阿里云 SSD 云盘作为数据持久化的方案,分别自动的为 mysql 和 minio 创建 SSD 云盘。
您可以在阿里云上尝试一下单独部署最新版本 Kubeflow Pipelines。
前提条件
- 您需要安装 kustomize
在 Linux 和 Mac OS 环境,可以执行
opsys=linux # or darwin, or windows
curl -s https://api.github.com/repos/kubernetes-sigs/kustomize/releases/latest |\
grep browser_download |\
grep $opsys |\
cut -d '"' -f 4 |\
xargs curl -O -L
mv kustomize_*_${opsys}_amd64 /usr/bin/kustomize
chmod u+x /usr/bin/kustomize
在 Windows 环境,可以下载 kustomize_2.0.3_windows_amd64.exe
- 在阿里云容器服务创建 Kubernetes 集群, 可以参考 文档
部署过程
- 通过 ssh 访问 Kubernetes 集群,具体方式可以参考文档
- 下载源代码
yum install -y git
git clone --recursive https://github.com/aliyunContainerService/kubeflow-aliyun
- 安全配置
3.1 配置 TLS 证书。如果没有 TLS 证书,可以通过下列命令生成
yum install -y openssl
domain="pipelines.kubeflow.org"
openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout kubeflow-aliyun/overlays/ack-auto-clouddisk/tls.key -out kubeflow-aliyun/overlays/ack-auto-clouddisk/tls.crt -subj "/CN=$domain/O=$domain"
如果您有 TLS 证书,请分别将私钥和证书保存到
kubeflow-aliyun/overlays/ack-auto-clouddisk/tls.key和kubeflow-aliyun/overlays/ack-auto-clouddisk/tls.crt下
3.2 配置 admin 的登录密码
yum install -y httpd-tools
htpasswd -c kubeflow-aliyun/overlays/ack-auto-clouddisk/auth admin
New password:
Re-type new password:
Adding password for user admin
- 首先利用 kustomize 生成部署 yaml
cd kubeflow-aliyun/
kustomize build overlays/ack-auto-clouddisk > /tmp/ack-auto-clouddisk.yaml
- 查看所在的 Kubernetes 集群节点所在的地域和可用区,并且根据其所在节点替换可用区,假设您的集群所在可用区为
cn-hangzhou-g, 可以执行下列命令
sed -i.bak 's/regionid: cn-beijing/regionid: cn-hangzhou/g' \
/tmp/ack-auto-clouddisk.yaml
sed -i.bak 's/zoneid: cn-beijing-e/zoneid: cn-hangzhou-g/g' \
/tmp/ack-auto-clouddisk.yaml
建议您检查一下 /tmp/ack-auto-clouddisk.yaml 修改是否已经设置
- 将容器镜像地址由
gcr.io替换为registry.aliyuncs.com
sed -i.bak 's/gcr.io/registry.aliyuncs.com/g' \
/tmp/ack-auto-clouddisk.yaml
建议您检查一下 /tmp/ack-auto-clouddisk.yaml 修改是否已经设置
- 调整使用磁盘空间大小, 比如需要调整磁盘空间为 200G
sed -i.bak 's/storage: 100Gi/storage: 200Gi/g' \
/tmp/ack-auto-clouddisk.yaml
- 验证 pipelines 的 yaml 文件
kubectl create --validate=true --dry-run=true -f /tmp/ack-auto-clouddisk.yaml
- 利用 kubectl 部署 pipelines
kubectl create -f /tmp/ack-auto-clouddisk.yaml
- 查看访问 pipelines 的方式,我们通过 ingress 暴露 pipelines 服务,在本例子中,访问 IP 是 112.124.193.271 。而 Pipelines 管理控制台的链接是: https://112.124.193.271/pipeline/
kubectl get ing -n kubeflow
NAME HOSTS ADDRESS PORTS AGE
ml-pipeline-ui * 112.124.193.271 80, 443 11m
- 访问 pipelines 管理控制台
如果使用自签发证书,会提示此链接非私人链接,请点击显示详细信息, 并点击访问此网站。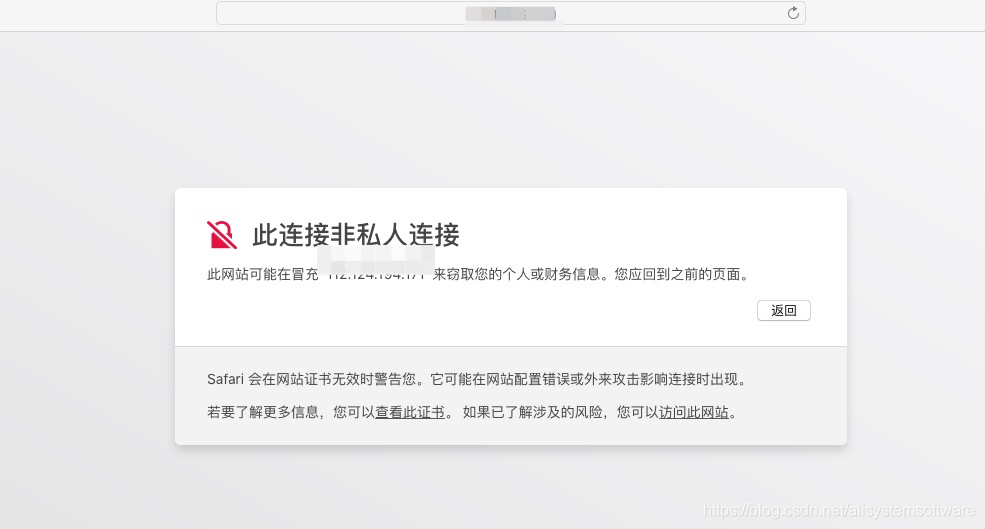
请输入步骤 2.2 中的用户名 admin 和设定的密码。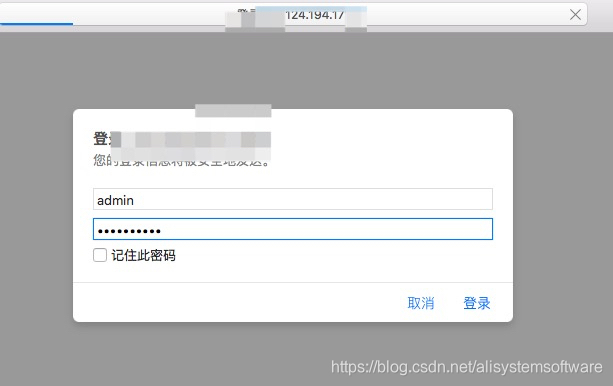
这时就可以使用 pipelines 管理和运行训练任务了。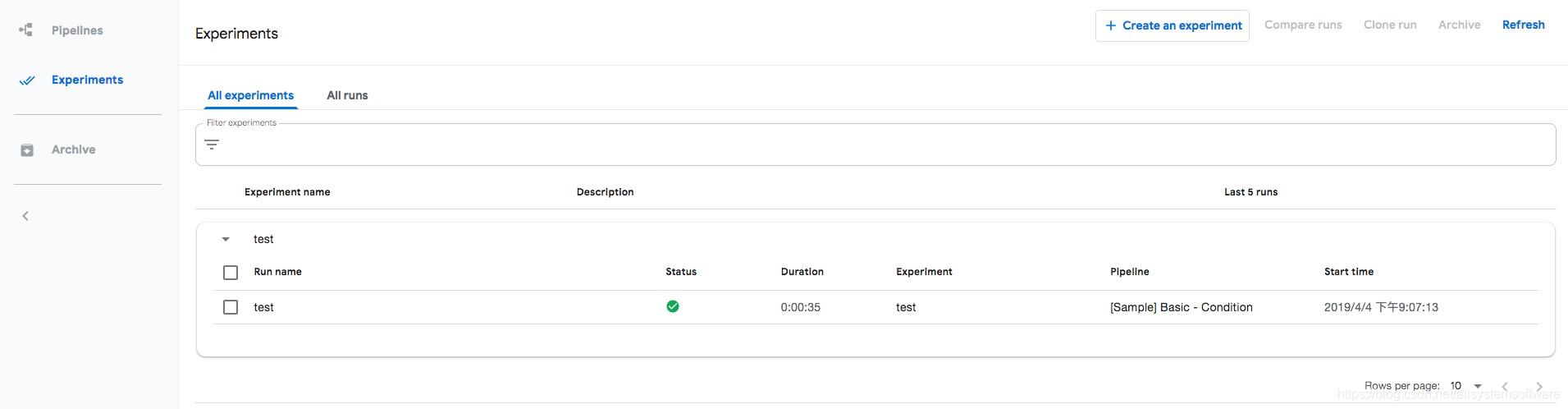
Q&A
- 为什么这里要使用阿里云的 SSD 云盘?
这是由于阿里云的 SSD 云盘可以设置定期的自动备份,保证 pipelines 中的元数据不会丢失。
- 如何进行云盘备份?
如果您想备份云盘的内容,可以为云盘 手动创建快照 或者 为硬盘设置自动快照策略 按时自动创建快照。
- 如何清理 Kubeflow Piplines 部署?
这里的清理工作分为两个部分:
- 删除 Kubeflow Pipelines 的组件
kubectl delete -f /tmp/ack-auto-clouddisk.yaml
- 通过释放云盘分别释放 mysql 和 minio 存储对应的两个云盘
- 如何使用现有云盘作为数据库存储,而避免自动创建云盘?
请参考文档
总结
本文为您初步介绍了 Kubeflow Pipelines 的背景和其所要解决的问题,以及如何在阿里云上通过 Kustomize 快速构建一套服务于机器学习的 Kubeflow Pipelines, 后续我们会分享如何利用 Kubeflow Pipelines 开发一个完整的机器学习流程。
目前尚无回复