推荐学习书目
› Learn Python the Hard Way
Python Sites
› PyPI - Python Package Index
› http://diveintopython.org/toc/index.html
› Pocoo
值得关注的项目
› PyPy
› Celery
› Jinja2
› Read the Docs
› gevent
› pyenv
› virtualenv
› Stackless Python
› Beautiful Soup
› 结巴中文分词
› Green Unicorn
› Sentry
› Shovel
› Pyflakes
› pytest
Python 编程
› pep8 Checker
Styles
› PEP 8
› Google Python Style Guide
› Code Style from The Hitchhiker's Guide
这是一个创建于 2906 天前的主题,其中的信息可能已经有所发展或是发生改变。
request.Request 实例重用时如何改变 URL 及 headers? PY3.5
下例中:翻页可以,但一旦选择书籍 id 就会抛出 HTTP Error 400: Bad Request 异常
比如:在书名输入时,输入 3 ,在结果中选择 0 (按 f 翻页不会)
将此时的网址提出来单独测试,却能正确打开!
问题出在哪里尚不知
from urllib import request,parse
import re
pat_books = re.compile() # 显示有问题见下面的回复
pat_home = re.compile() # 显示有问题见下面的回复
headers = {
"Referer":"http://so.mianhuatang.la/",
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36\
(KHTML, like Gecko) Chrome/42.0.2311.90 Safari/537.36"
}
class Search_req: #
def __init__(self):
self.url = r'http://so.mianhuatang.la/cse/search?q={}&p={}&s=7965856832468911224&entry=1'
self.books = [] # 书籍(章节)列表 [(url,name),]
self.bkname = ''
self.req = request.Request(self.url,headers=headers)
def _search(self,url):
self.req.full_url = url
print(url)
with request.urlopen(self.req) as htm:
return htm.read()
def searchBooks(self,page): # 书目 可能抛异常
global pat_books
url = self.url.format(parse.quote(self.bkname),page)
res = self._search(url).decode('utf-8','ignore')
self.books = pat_books.findall(res)
def searchHome(self,homeUrl): # 搜索书籍主目录的章节列表
global pat_home # 章节列表[(url,name),]
res = self._search(homeUrl).decode('gbk','ignore')
self.books = pat_home.findall(res)
def showMenu(books,page):
print('\n\t 第 {} 页'.format(page+1))
for i,book in enumerate(books):
print('{}: {}'.format(i,book[1]))
def main(): # 节选
s = Search_req()
while True:
s.bkname = input('\n 网络小说搜索 [回车退出] :').strip()
if not s.bkname: break
for page in range(10):
try:
s.searchBooks(page) # 获取书目
if not s.books: break
showMenu(s.books,page) # 显示书籍搜索结果
id = input('请根据序号选择(f:翻页 q:退出):').lower()
if id == 'q' : return
if id == 'f': continue
homeurl,s.bkname = s.books[int(id)] #获得所选书籍主页[url,name]
s.searchHome(homeurl) # 获取主页上的章节列表
print('test: END')
break
except Exception as err:
print(str(err))
break
if name == 'main': # 这里应为__main__
url = r'http://www.mianhuatang.la/31/31605/' # 提出来单独测试
req = request.Request(url,headers=headers)
with request.urlopen(req) as htm:
print('ok')
main() # 主测试
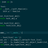 |
1
explist OP pat_books = re.compile(r'<a\s+cpos="title"\s*href="(.+?)"\s*title="(.+?)"')
pat_home = re.compile(r'(?<=<dd><a href=")(.+?)">(.+?)</a>') |