推荐学习书目
› Learn Python the Hard Way
Python Sites
› PyPI - Python Package Index
› http://diveintopython.org/toc/index.html
› Pocoo
值得关注的项目
› PyPy
› Celery
› Jinja2
› Read the Docs
› gevent
› pyenv
› virtualenv
› Stackless Python
› Beautiful Soup
› 结巴中文分词
› Green Unicorn
› Sentry
› Shovel
› Pyflakes
› pytest
Python 编程
› pep8 Checker
Styles
› PEP 8
› Google Python Style Guide
› Code Style from The Hitchhiker's Guide

这是一个创建于 2200 天前的主题,其中的信息可能已经有所发展或是发生改变。
DDTW 导数动态时间规整算法
作者:郑培
Derivative Dynamic Time Warping ( DDTW ) 是对 Dynamic Time Warping (DTW) 的一种改进。缓解了经典 DTW 算法所产生的“奇点”( Singularities )问题,本文将从以下几个方面介绍 DDTW 算法。
1、算法背景
时间序列是几乎每一个科学学科中普遍存在的数据形式。时间序列的常见处理任务是将一个序列与另一个序列进行比较,以比较两个时间序列的相似度。在某些领域,使用非常简单的距离度量(例如欧式距离)就足够了。
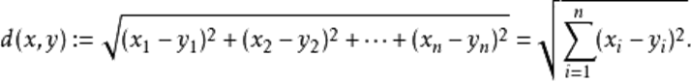
但是,在大多情况下,两个序列的总体组成形状大致相同,但是这些形状在 X 轴上并不对齐。(图 1 )
为了找到这些序列之间的相似性,或作为对它们进行平均之前的预处理步骤,我们必须“扭曲”一个(或全部两个)序列的时间轴以实现更好的比对。动态时间规整( DTW )是一种有效实现这种规整的技术。
例如图 A 所示,实线和虚线分别是同一个词“pen”的两个语音波形(在 y 轴上拉开了,以便观察)。可以看到他们整体上的波形形状很相似,但在时间轴上却是不对齐的,假设一个序列中的第 i 个点与另一序列中的第 i 个点对齐将产生“悲观差异”( pessimistic dissimilarity )。而在图 B 中,DTW 就可以通过找到这两个波形对齐的点,这样计算它们的距离才是正确的。
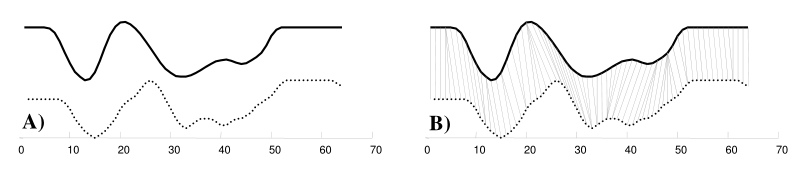 (图 1 )
因此,DTW 显示出了很好的能力,除了在数据挖掘( Keogh & Pazzani 2000,Yi et. al.1998,Berndt & Clifford 1994 )上的应用,DTW 还被用于手势识别( Gavrila & Davis 1995 ),机器人技术( Schmill et. al 1999 ),语音处理( Rabiner & Juang 1993 ),制造业( Gollmer & Posten 1995 )和医药行业( Caiani et. al 1998 )。
(图 1 )
因此,DTW 显示出了很好的能力,除了在数据挖掘( Keogh & Pazzani 2000,Yi et. al.1998,Berndt & Clifford 1994 )上的应用,DTW 还被用于手势识别( Gavrila & Davis 1995 ),机器人技术( Schmill et. al 1999 ),语音处理( Rabiner & Juang 1993 ),制造业( Gollmer & Posten 1995 )和医药行业( Caiani et. al 1998 )。
2、经典动态时间规整算法
假设我们有两个时间序列 Q 和 C,长度分别为 n 和 m,其中:
 为了对齐这两个序列,我们需要构造一个 n x m 的矩阵网格,矩阵元素(i, j)表示 qi 和 cj 两个点的距离 d(qi, cj)(也就是序列 Q 的每一个点和 C 的每一个点之间的相似度,距离越小则相似度越高。这里先不管顺序),一般采用欧式距离。每一个矩阵元素(i, j)表示点 qi 和 cj 的对齐。有了这个矩阵,我们就能够对两个时间序列之间的距离进行计算,并显示出一条规整路径 warping path ( W )。由于有许多不同的对时间轴的“扭曲”方式,因此我们能够得到很多条规整路径( W 的公式如下),但我们的目标是找到一条最短的规整路径,以判断两条时间序列之间的“距离”也就是相似度,而如何快速地找到这条路径呢?我们发现动态规划( Dynamic Programming )可以为我们提供很大的方便。
Dynamic Programming 算法可以归结为寻找一条通过此网格中若干格点的路径,路径通过的格点即为两个序列进行计算的对齐的点。
为了对齐这两个序列,我们需要构造一个 n x m 的矩阵网格,矩阵元素(i, j)表示 qi 和 cj 两个点的距离 d(qi, cj)(也就是序列 Q 的每一个点和 C 的每一个点之间的相似度,距离越小则相似度越高。这里先不管顺序),一般采用欧式距离。每一个矩阵元素(i, j)表示点 qi 和 cj 的对齐。有了这个矩阵,我们就能够对两个时间序列之间的距离进行计算,并显示出一条规整路径 warping path ( W )。由于有许多不同的对时间轴的“扭曲”方式,因此我们能够得到很多条规整路径( W 的公式如下),但我们的目标是找到一条最短的规整路径,以判断两条时间序列之间的“距离”也就是相似度,而如何快速地找到这条路径呢?我们发现动态规划( Dynamic Programming )可以为我们提供很大的方便。
Dynamic Programming 算法可以归结为寻找一条通过此网格中若干格点的路径,路径通过的格点即为两个序列进行计算的对齐的点。
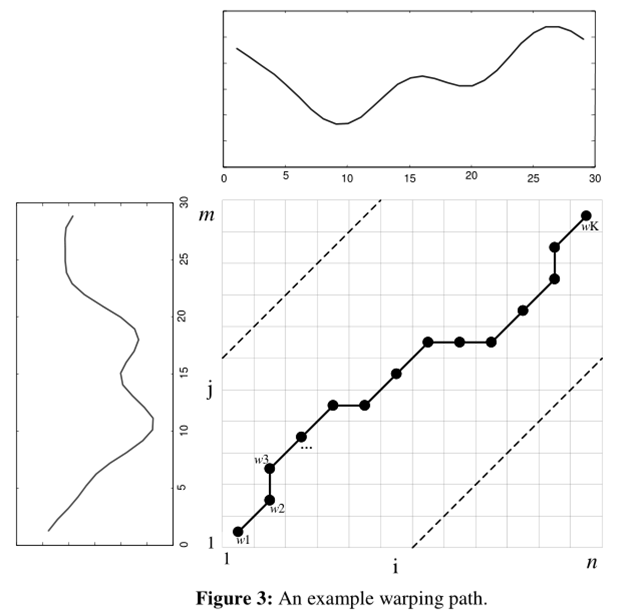
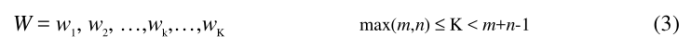 w 的第 i 个元素为 w=(i,j)定义了两条时间序列的映射。并且,规整路径一般受到以下几种约束条件。
1 )边界条件:定义了规整路径必须在矩阵的对角元素中开始和结束;
2 )连续性:这将规整路径中的允许步骤限制为相邻的单元(包括对角相邻的单元);
3 )单调性:这迫使 W 中的点在时间上单调进行。
w 的第 i 个元素为 w=(i,j)定义了两条时间序列的映射。并且,规整路径一般受到以下几种约束条件。
1 )边界条件:定义了规整路径必须在矩阵的对角元素中开始和结束;
2 )连续性:这将规整路径中的允许步骤限制为相邻的单元(包括对角相邻的单元);
3 )单调性:这迫使 W 中的点在时间上单调进行。
结合连续性和单调性约束,每一个格点的路径就只有三个方向了。例如如果路径已经通过了格点(i, j),那么下一个通过的格点只可能是下列三种情况之一:(i+1, j),(i, j+1)或者(i+1, j+1)。
 由上文所述,我们可以通过比较满足以上条件所有规整路径找出最短的规整路径,但是 DP 为我们提供了一个更好地方法来计算最短路径。我们首先定义一个累积距离 cumulative distance γ,累积距离γ(i,j)为当前格点距离 d(i,j),也就是点 qi 和 cj 的欧式距离与可以到达该点的最小的邻近元素的累积距离之和:
由上文所述,我们可以通过比较满足以上条件所有规整路径找出最短的规整路径,但是 DP 为我们提供了一个更好地方法来计算最短路径。我们首先定义一个累积距离 cumulative distance γ,累积距离γ(i,j)为当前格点距离 d(i,j),也就是点 qi 和 cj 的欧式距离与可以到达该点的最小的邻近元素的累积距离之和:
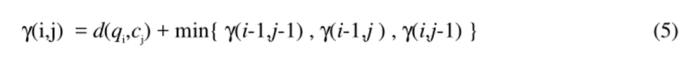 通过动态规划算法,我们可以较简单地得到最短的累积距离。
通过动态规划算法,我们可以较简单地得到最短的累积距离。
3、动态时间规划的“奇点”问题
DTW 算法最重要的特征就是通过“扭曲”X 轴来解释 Y 轴变量,以达到使时间序列对齐的目的。但是简单的通过 Y 轴的变量值来扭曲 X 轴会导致“不直观”( unintuitive )的对齐,其中一个时间序列上的单个点会映射到另一个时间序列的一部分上。我们称这种我们不期望看到的行为为“奇点”( singularities )。
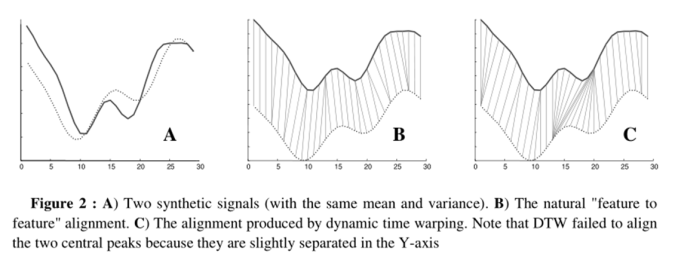
已经提出了很多临时的方法来缓解这种奇点问题,这些方法都具有一个共同点,即基本上都限制了可能的“扭曲”。但是,它们造成的缺点是,可能阻止发现“正确的”“扭曲”。 因此,我们引入了 Derivative DTW 来改进这种问题。
4、导数动态时间规整算法
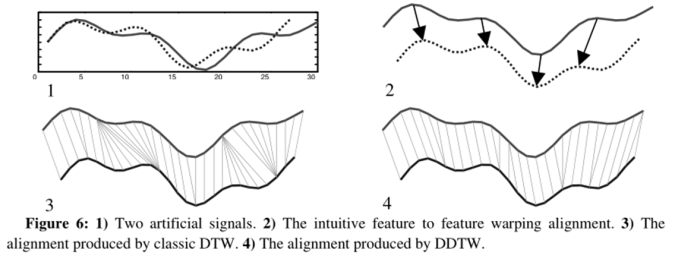
如前文所述,DTW 算法粗暴地( wildly )根据 Y 轴变量的值对 X 轴进行 warp,这样在 Y 轴变量有细微变动时很容易造成奇点问题,如下图所示。而最正确的时间序列的对齐应该是特征之间的对应( feature to feature ),于是我们考虑比 DTW 更高一层次的特征选取,根据形状( shape )来进行对齐。
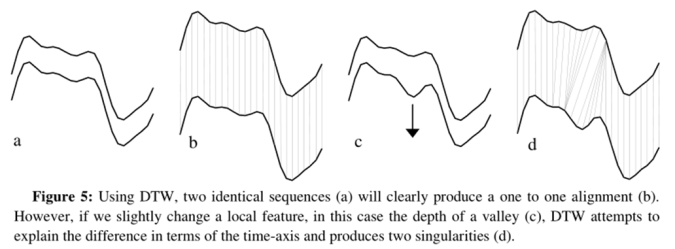
4.1、DDTW 算法细节
那么如何才能获取关于形状的信息,我们知道一阶导数可以反映斜率,而斜率是我们判断时间序列形状的一个指数,因此我们通过考虑序列的一阶导数来获得有关形状的信息,因此将我们的算法称为 Derivative
Dynamic Time Warping(DDTW)。
如前所述,我们构造了一个 n×m 矩阵,其中矩阵的( i th,j th )元素包含两个点 q i 和 c j 之间的距离 d ( q i,c j )。DTW 算法根据欧式距离来计算两个时间序列对应点之间的距离,DDTW 则通过 qi 和 cj 之间估计导数差值的平方来代替 DTW 算法的距离公式。在这里我们不去考虑繁琐精确的一阶导数计算公式,反之我们使用简单的导数估计方法,以增加方法的泛化性。估计导数公式如下:
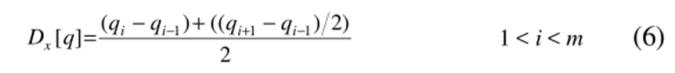 大家可以看到,该估计值只是通过该点及其左邻点的直线的斜率以及通过左邻点和右邻点的直线的斜率的平均值来得出的。值得注意的是该公式比仅利用两个数据点对于离群点更具有鲁棒性。另外值得注意的是该公式并不包括第一个与最后一个点,反之是运用第二个点与倒数第二个点来代替。
大家可以看到,该估计值只是通过该点及其左邻点的直线的斜率以及通过左邻点和右邻点的直线的斜率的平均值来得出的。值得注意的是该公式比仅利用两个数据点对于离群点更具有鲁棒性。另外值得注意的是该公式并不包括第一个与最后一个点,反之是运用第二个点与倒数第二个点来代替。
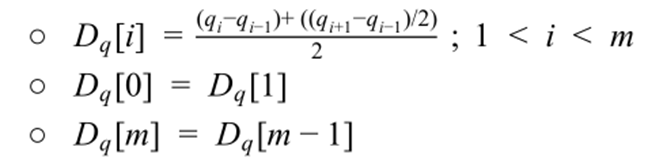 以下是简单的一个例子。
以下是简单的一个例子。
5、实验与结果
为了验证 DDTW 对于奇点问题的改进,作者设计了两个实验分别从正反两个方面来进行论证。
5.1 错误的规整( spurious warping )
作者选取了三类在形状,噪声和自相关方面相差很大的三组数据集来进行实验。这些序列高度相关但不完全相同,特别是它们包含较小的(局部)差异。

为了简便地对比两种算法的差异,我们采用较为简单的 K 值(规整路径的长度)来进行计算。其中 K 的取值范围在 max(m,n)<K<m+n-1。同时由于在该实验中两条时间序列的长度相似,因此 m ≤ K < 2m-1。于是我们定义 W 为 warp 的次数,因此我们得到以下公式:

W 可以反映两种算法 warp 扭曲的次数,如果算法在两个序列之间没有发现扭曲,则 W 将等于零;扭曲越多,发现 W 的值越大。对于上文所述三个数据集,我们进行多次实验并取平均值后得到以下结果:
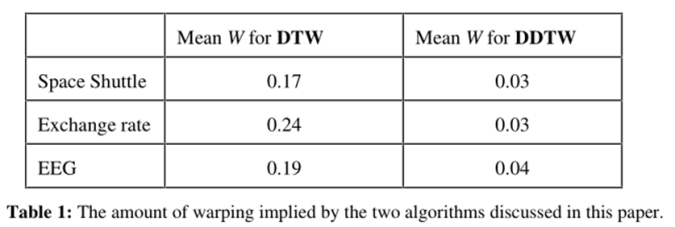
通过实验,DTW 尝试粗暴( wild )的通过时间轴的扭曲来纠正序列之间的微小差异。相应的 DDTW 则因为考虑“更高层次的特征”从而更不容易发现不存在的 warp。
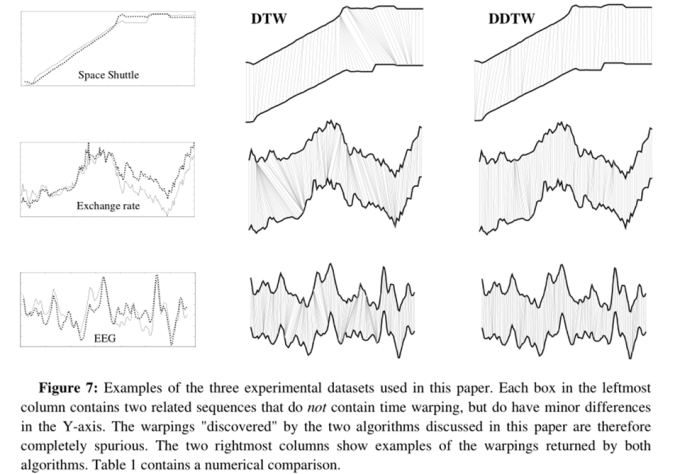 在这里值得注意的是,由于这三组时间序列是高度相关但不相同的,并且在 Y 轴上包含细微的差别,所以对于这三组时间序列分别的 warp 其实是完全错误的( completely spurious )。也就是说两种算法找到的 warp 越多,那么他们对于奇点问题的识别排出就越差。因此我们可以看到,DDTW 在奇点问题上对于 DTW 具有很大的提升。
在这里值得注意的是,由于这三组时间序列是高度相关但不相同的,并且在 Y 轴上包含细微的差别,所以对于这三组时间序列分别的 warp 其实是完全错误的( completely spurious )。也就是说两种算法找到的 warp 越多,那么他们对于奇点问题的识别排出就越差。因此我们可以看到,DDTW 在奇点问题上对于 DTW 具有很大的提升。
5.2 寻找正确的“扭曲”( find the correct warping )
该实验是为了验证两种算法对于需要 warp 的时间序列的敏感性。因此作者通过一条时间序列 Q 与时间序列 Q 的复制 Q'来进行实验。简单来说,作者通过对时间序列 Q'插入三种不同水平的 Gaussian bump 以达到对时间序列在 Y 轴上的细微变化,再通过两种算法对时间序列 Q 和 Q'进行 warp,观察算法的效果。
与第一个实验相同,我们设定 M 为错误 warp 的次数,并且在以下条件下得到公式:
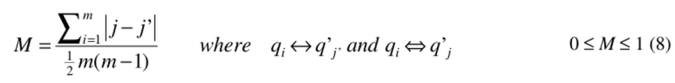
条件中的双箭头对应表示时间序列 Q 与 Q'之间正确的对应关系,单箭头对应表示由算法返回的实际对应关系。当且仅当两个条件都符合时,我们计算两条时间序列对应 Y 轴变量的差值。公示中分母是为了标准化而做的计算。
分析公式 8 我们可以知道,当时间序列上对应点正确匹配时,差值为零,如果算法产生了很多奇点,那么 M 的值就会越大,因此我们可以通过该公式比较两种算法对于寻找正确 warp 的能力。实验结果如下:
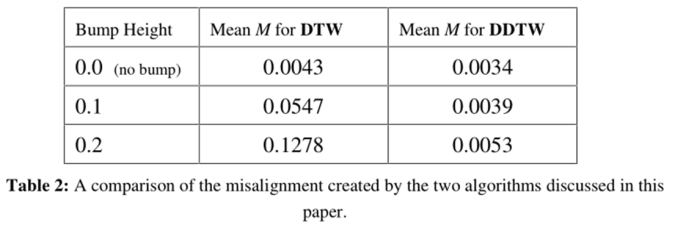
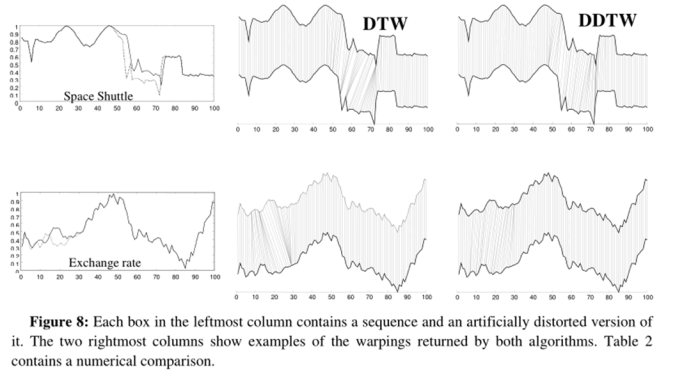
由以上实验可知,DDTW 可在时间序列之间产生出色的对齐方式;并且 DDTW 可以更好地找到两个序列之间的正确变形。
6、参考资料
论文:Eamonn J. Keogh, Derivative Dynamic Time Warping 暂无论文实验数据,仅提供参考代码,供大家学习理解:https://momodel.cn/explore/5d837ba0870b9dc68fd13fdc?type=app
关于我们
Mo(网址:https://momodel.cn)是一个支持 Python 的人工智能在线建模平台,能帮助你快速开发、训练并部署模型。
Mo 人工智能俱乐部 是由网站的研发与产品设计团队发起、致力于降低人工智能开发与使用门槛的俱乐部。团队具备大数据处理分析、可视化与数据建模经验,已承担多领域智能项目,具备从底层到前端的全线设计开发能力。主要研究方向为大数据管理分析与人工智能技术,并以此来促进数据驱动的科学研究。
目前俱乐部每两周在杭州举办线下论文分享与学术交流。希望能汇聚来自各行各业对人工智能感兴趣的朋友,不断交流共同成长,推动人工智能民主化、应用普及化。

目前尚无回复