
Bert 做中文分类任务,使用的模型是哈工大讯飞开源的中文预训练模型 roberta-wwm-large,按照网上的教程修改了 run-classifier.py ,然后运行之后报了 KeyError 的错。
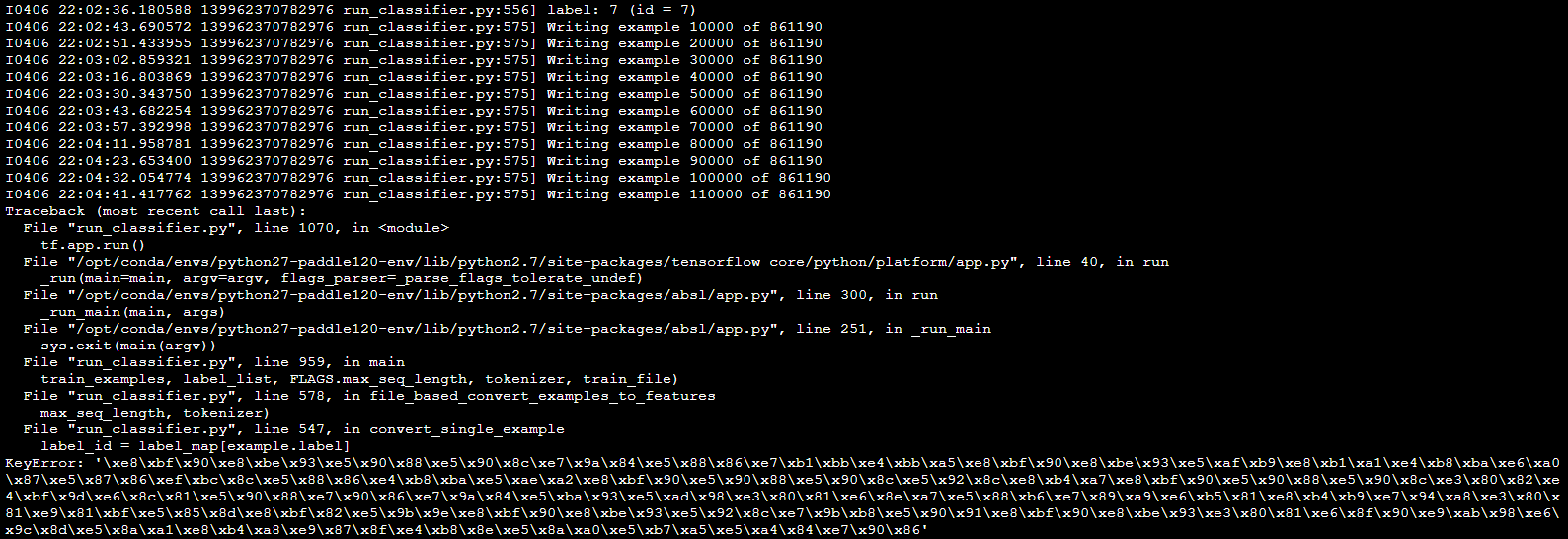 已经加载了 110000 条数据的情况下报错,感觉应该是 id 为 110000 多的某条数据有问题,但是是什么问题并不清楚,请看官们分析一下。
我将 csv 格式的数据集的 label 一列打印,是 0-10 的 11 个数字没错,并没有出现 keyerror 后面的中文,但是根据报错的信息应该是我的 label 错了,我不知道是什么情况,难顶。
已经加载了 110000 条数据的情况下报错,感觉应该是 id 为 110000 多的某条数据有问题,但是是什么问题并不清楚,请看官们分析一下。
我将 csv 格式的数据集的 label 一列打印,是 0-10 的 11 个数字没错,并没有出现 keyerror 后面的中文,但是根据报错的信息应该是我的 label 错了,我不知道是什么情况,难顶。
This topic created in 2234 days ago, the information mentioned may be changed or developed.
 |
1
clockwise9 Apr 28, 2020 via Android
莫非是字符串编码问题。。。
|