
这是一个创建于 1998 天前的主题,其中的信息可能已经有所发展或是发生改变。
1
前段时间,在网上看到一道面试题:
如何用 redis 存储统计 1 亿用户一年的登陆情况,并快速检索任意时间窗口内的活跃用户数量。
觉得很有意思,就仔细想了下 。并做了一系列实验,自己模拟了下 。还是有点收获的,现整理下来。和大家一起分享。
Redis 是一个内存数据库,采用单线程和事件驱动的机制来处理网络请求。实际生产的 QPS 和 TPS 单台都能达到 3,4W,读写性能非常棒。用来存储一些对核心业务弱影响的用户状态信息还是非常不错的。
对于这题,有 2 个重要的点需要考虑:
1.如何用合适的数据类型来存储 1 亿用户的数据,用普通的字符串来存储肯定不行。经过查看一个最简单的 kv(key 为 aaa,value 为 1)的内存占用,发现为 48byte 。

假设每个用户每天登陆需要占据 1 对 KV 的话,那一亿就是(48*100000000)/1024/1024/1024=4.47G 。这还是一天的量。
2.如何满足搜索,redis 是一个键值对的内存结构,只能根据 key 来进行定位 value 值,无法做到像 elastic search 那样对文档进行倒排索引快速全文检索。
redis 其实有这种数据结构的,可以以很少的空间来存储大量的信息。
##2
在 redis 2.2.0 版本之后,新增了一个位图数据,其实它不是一种数据结构。实际上它就是一个一个字符串结构,只不过 value 是一个二进制数据,每一位只能是 0 或者 1 。redis 单独对 bitmap 提供了一套命令。可以对任意一位进行设置和读取。
bitmap 的核心命令:
SETBIT
语法:SETBIT key offset value
例如:
setbit abc 5 1 ----> 00001
setbit abc 2 1 ----> 00101
GETBIT
语法:GETBIT key offset
例如:
getbit abc 5 ----> 1
getbit abc 1 ----> 0
bitmap 的其他命令还有 bitcount,bitcount,bitpos,bitop 等命令。都是对位的操作。
因为 bitmap 的每一位只占据 1bit 的空间 ,所以利用这个特性我们可以把每一天作为 key,value 为 1 亿用户的活跃度状态。假设一个用户一天内只要登录了一次就算活跃。活跃我们就记为 1,不活跃我们就记为 0 。把用户 Id 作为偏移量(offset)。这样我们一个 key 就可以存储 1 亿用户的活跃状态。
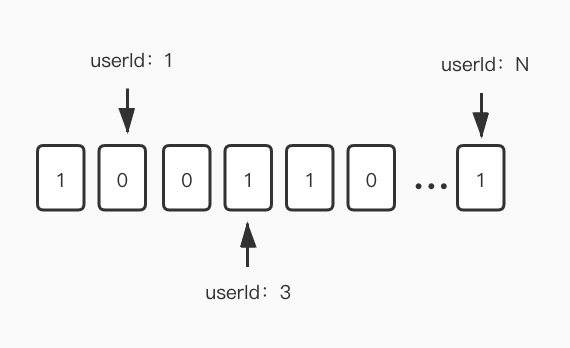
我们再来算下,这样一个位图结构的值对象占据多少空间。每一个位是 1bit,一亿用户就是一亿 bit 。8bit=1Byte
100000000/8/1024/1024=11.92M
我用测试工程往一个 key 里通过 lua 塞进了 1 亿个 bit,然后用 rdb tools 对内存进行统计,实测如下:

一天 1 亿用户也就消耗 12M 的内存空间。这完全符合要求。1 年的话也就 4 个 G 。几年下来的话,redis 可以集群部署来进行扩容存储。我们也可以用位图压缩算法对 bitmap 进行压缩存储。例如 WAH,EWAH,Roaring Bitmaps 。这个以后可以单独拉出来聊聊。
我们把每一天 1 亿用户的登陆状态都用 bitmap 的形式存进了 redis,那要获取某一天 id 为 88000 的用户是否活跃,直接使用getbit命令:
getbit 2020-01-01 88000 [时间复杂度为 O(1)]
如果要统计某一天的所有的活跃用户数,使用bitcount命令,bitcount 可以统计 1 的个数,也就是活跃用户数:
bitcount 2019-01-01 [时间复杂度为 O(N)]
如果要统计某一段时间内的活跃用户数,需要用到 bitop 命令。这个命令提供四种位运算,AND(与),(OR)或,XOR(亦或),NOT(非)。我们可以对某一段时间内的所有 key 进行OR(或)操作,或操作出来的位图是 0 的就代表这段时间内一次都没有登陆的用户。那只要我们求出 1 的个数就可以了。以下例子求出了 2019-01-01 到 2019-01-05 这段时间内的活跃用户数。
bitop or result 2019-01-01 2019-01-02 2019-01-03 2019-01-04 2019-01-05 [时间复杂度为 O(N)]
bitcount result
从时间复杂度上说,无论是统计某一天,还是统计一段时间。在实际测试时,基本上都是秒出的。符合我们的预期。
3
bitmap 可以很好的满足一些需要记录大量而简单信息的场景。所占空间十分小。通常来说使用场景分 2 类:
1.某一业务对象的横向扩展,key 为某一个业务对象的 id,比如记录某一个终端的功能开关,1 代表开,0 代表关。基本可以无限扩展,可以记录 2^32 个位信息。不过这种用法由于 key 上带有了业务对象的 id,导致了 key 的存储空间大于了 value 的存储空间,从空间使用角度上来看有一定的优化空间。
2.某一业务的纵向扩展,key 为某一个业务,把每一个业务对象的 id 作为偏移量记录到位上。这道面试题的例子就是用此法来进行解决。十分巧妙的利用了用户的 id 作为偏移量来找到相对应的值。当业务对象数量超过 2^32 时(约等于 42 亿),还可以分片存储。
看起来 bitmap 完美的解决了存储和统计的问题。那有没有比这个更加省空间的存储吗?
答案是有的。
4
redis 从 2.8.9 之后增加了 HyperLogLog 数据结构。这个数据结构,根据 redis 的官网介绍,这是一个概率数据结构,用来估算数据的基数。能通过牺牲准确率来减少内存空间的消耗。
我们先来看看 HyperLogLog 的方法
PFADD 添加一个元素,如果重复,只算作一个
PFCOUNT 返回元素数量的近似值
PFMERGE 将多个 HyperLogLog 合并为一个 HyperLogLog
这很好理解,是不是。那我们就来看看同样是存储一亿用户的活跃度,HyperLogLog 数据结构需要多少空间。是不是比 bitmap 更加省空间呢。
我通过测试工程往 HyperLogLog 里 PFADD 了一亿个元素。通过 rdb tools 工具统计了这个 key 的信息:

只需要 14392 Bytes !也就是 14KB 的空间。对,你没看错。就是 14K 。bitmap 存储一亿需要 12M,而 HyperLogLog 只需要 14K 的空间。
这是一个很惊人的结果。我似乎有点不敢相信使用如此小的空间竟能存储如此大的数据量。
接下来我又放了 1000w 数据,统计出来还是 14k 。也就是说,无论你放多少数据进去,都是 14K 。
查了文档,发现 HyperLogLog 是一种概率性数据结构,在标准误差 0.81%的前提下,能够统计 2^64 个数据。所以 HyperLogLog 适合在比如统计日活月活此类的对精度要不不高的场景。
HyperLogLog 使用概率算法来统计集合的近似基数。而它算法的最本源则是伯努利过程。
伯努利过程就是一个抛硬币实验的过程。抛一枚正常硬币,落地可能是正面,也可能是反面,二者的概率都是 1/2 。伯努利过程就是一直抛硬币,直到落地时出现正面位置,并记录下抛掷次数 k 。比如说,抛一次硬币就出现正面了,此时 k 为 1; 第一次抛硬币是反面,则继续抛,直到第三次才出现正面,此时 k 为 3 。
对于 n 次伯努利过程,我们会得到 n 个出现正面的投掷次数值 k1, k2 ... kn , 其中这里的最大值是 k_max 。
根据一顿数学推导,我们可以得出一个结论:2^{k_ max} 来作为 n 的估计值。也就是说你可以根据最大投掷次数近似的推算出进行了几次伯努利过程。
5
虽然 HyperLogLog 数据类型这么牛逼,但终究不是精确统计。只适用于对精度要求不高的场景。而且这种类型无法得出每个用户的活跃度信息。毕竟只有 14K 嘛。也不可能存储下那么多数量的信息。
总结一下:对于文章开头所提到的面试题来说,用 bitmap 和 HyperLogLog 都可以解决。
bitmap 的优势是:非常均衡的特性,精准统计,可以得到每个统计对象的状态,秒出。缺点是:当你的统计对象数量十分十分巨大时,可能会占用到一点存储空间,但也可在接受范围内。也可以通过分片,或者压缩的额外手段去解决。
HyperLogLog 的优势是:可以统计夸张到无法想象的数量,并且占用小的夸张的内存。 缺点是:建立在牺牲准确率的基础上,而且无法得到每个统计对象的状态。
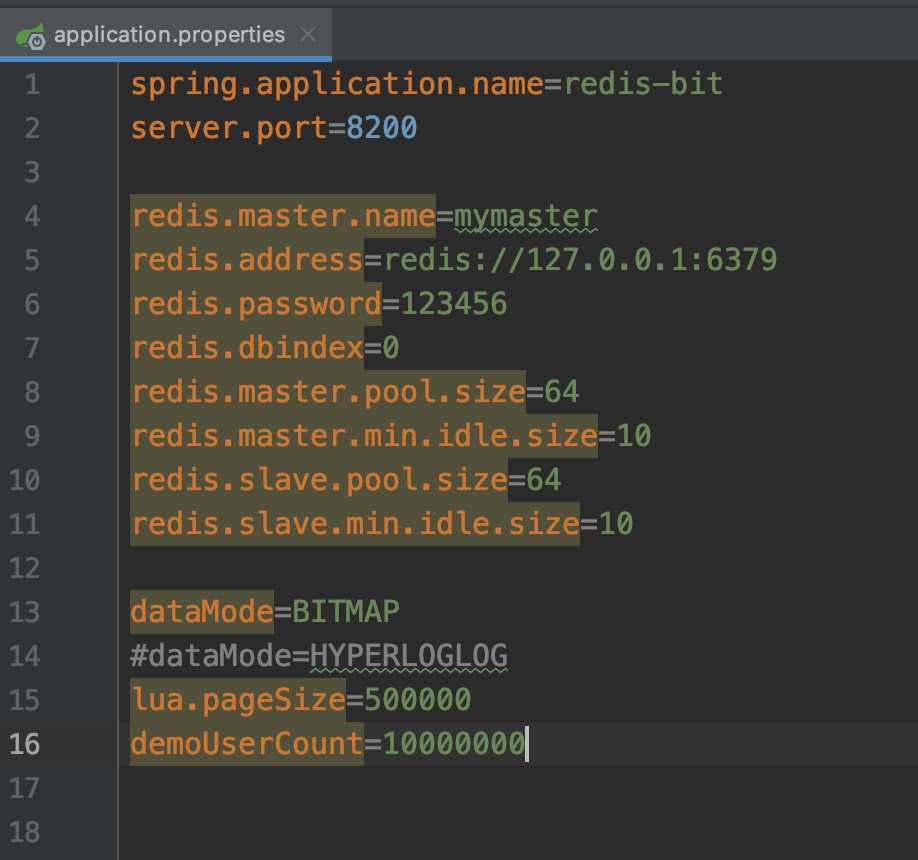
我做了一个演示工程 redis-bit,在公众号里回复 redis 即可获取到这个案例,工程包括了初始化大容量的数据。和分别使用 bitmap 和 HyperLogLog 进行用户活跃度的统计。最后通过 http 的方式进行输出。
工程采用 springboot+redisson 客户端。所有的参数支持配置
6
觉得有用的话,请关注下我的公众号「元人部落」,作者坚持原创的内容技术分享,也有开源作品,欢迎关注
开源仓库为: https://gitee.com/bryan31
公众号一般周更,每次会分享一些实用的技术,陪你一起成长
关注后回复“资料”领取 50G 的视频资料,包括一套企业级微服务的视频教学

 |
1
hackerang 2020 年 8 月 28 日
很不错啊!!
|
 |
2
takemeaway 2020 年 8 月 28 日
这样好是好,可是我想问,为什么不直接把登录次数设计成一天登录就加一次?
|
 |
3
bryan31 OP @takemeaway 有 bit 组数去存,只有 0 和 1 两种。
|
 |
4
BBCCBB 2020 年 8 月 28 日
@takemeaway 说了任意时间窗口啊.
|
 |
5
limboMu 2020 年 8 月 28 日
@takemeaway 技术无法精准到哪天登录了呀
|
 |
8
goobai 2020 年 8 月 28 日 via Android
redis 最合适的应用场景不应该是缓存嘛?
|

 |
10
fantastM 2020 年 8 月 28 日
> 把用户 Id 作为偏移量(offset)
假如 userId 是字符串类型( uuid )的时候要怎么办呢 |
|
11
bryan31 OP @fantastM 可以进行变换,比如取 uuid 的 hashode,UUID.randomUUID().toString().hashCode()
当然有可能为负数,负数的话可以直接取绝对值再加一亿,上文说了,存一亿个值才 12M,那你设计一个 2 亿位数的值对象,也才 24M 。 |
|
16
bryan31 OP 这个方案着重于记录用户这一天是否登录过,具体何时登录,其实并不关心。如果要记录具体登录信息。那一亿用户的存储量就大了。这个方案不适用了。每个方案都有取舍,没有最完美的方案,只有最合适的
|
 |
18
hsuvee 2020 年 8 月 28 日
楼主发帖可不可以不带推广,v 站都有了公众号既视感
|
 |
20
hhhWhy 2020 年 8 月 28 日
公众号不说,东西是可以的,HyperLogLog 还能展开在说说
|
 |
21
VoidChen 2020 年 8 月 28 日
这是你写的吗。其实这种做法很久之前就有了,不过我那会是把二进制 01 当字符串去处理了,虽然也实想了压缩数据的目的但是现在想想觉得有点 low,不知道 redis 底层是怎么实现对这个二进制数进行位操作的,难道是数组?这个倒是可以掰开说说啊
|
 |
22
zivn 2020 年 8 月 28 日 每天一个 key,一亿人用,你这妥妥是个热 key 啊,要是 codis 或者 redis cluster,某个点就被打死了;
应该把用户 ID 取余 2 的 n 次方,分 2 的 n 次方个 key 来存,虽然统计会稍微麻烦点儿,但基本不影响写入,散列开还能提升 HyperLogLog 准确度; 分布式存储架构,最怕热 key 了,上线会死的很惨,特别是 redis 这种单线程的,出事就是连锅端了; |
 |
23
msaionyc 2020 年 8 月 28 日
不错
|
 |
24
tf2 2020 年 8 月 28 日 标题不错。拉到最后看下有没有推广。。
有。那行。关闭文章。 |
 |
25
duteliang 2020 年 8 月 28 日
思路还是不错的。学到了。
|
 |
28
vanyj 2020 年 8 月 28 日
放个屁的公众号,带公众号引流的一向不看
|


|
31
VoidChen 2020 年 8 月 28 日
@bryan31 能存没问题,关键是存的是一个 int 类型的数字还是一个 char 数组,如果是二进制数字的话按位操作,其实是对这个数字做加减吧
|
 |
32
Hallelu 2020 年 8 月 28 日 我觉得好的营养文章带推广并没有什么,那种完全博取眼球标题党的推广才是可恨
|
 |
34
anthow 2020 年 8 月 28 日
不错,思路学习了
|
 |
35
black11black 2020 年 8 月 29 日
很不错,不过我一直好奇一个场景是如何做到的,比如博主提到的日活,一天只产生一次数据,那像微博那种点踩点赞系统呢,即使用这种方式存也装不下吧,微博评论上千亿,然后还要记录我对其中哪一条点了赞,实在神奇
|
|
36
black11black 2020 年 8 月 29 日
@black11black 另外这种储存方式应该不支持 bit 级别的偏移读取吧,那是不是每一次加载日活信息就要一次性载入 12M 的全部内存数据
|
|
37
bryan31 OP @black11black 支持的,支持 bit 级别的偏移读取,如果每加载一次就要一次性载入 12M 的数据,那这个就没什么意义了。我做的例子里面有完整的示例,redis 原生支持 getbit,setbit,支持读取指定位的那个 bit,写入指定位置的 bit
|


