
这是一个创建于 165 天前的主题,其中的信息可能已经有所发展或是发生改变。
TLDR
-
WHAT: 介绍并复现 DeepMind 的一篇关于 LLM Speculative Sampling 的论文:Accelerating large language model decoding with speculative sampling. 我们将用不到 100 行代码来复现这篇论文,并得到 2 倍以上的速度提升。
-
亮点:基于 GPT2, 代码,模型权重全部可以下载并本地运行;只需要 16GB 的显存即可完整本地复现。
-
公众号文章(内容同博客,便于收藏): https://mp.weixin.qq.com/s/3rFk8cgJuxjW30A4-emhEA
-
代码: https://github.com/ai-glimpse/toyllm/tree/master/toyllm/sps
具体实现
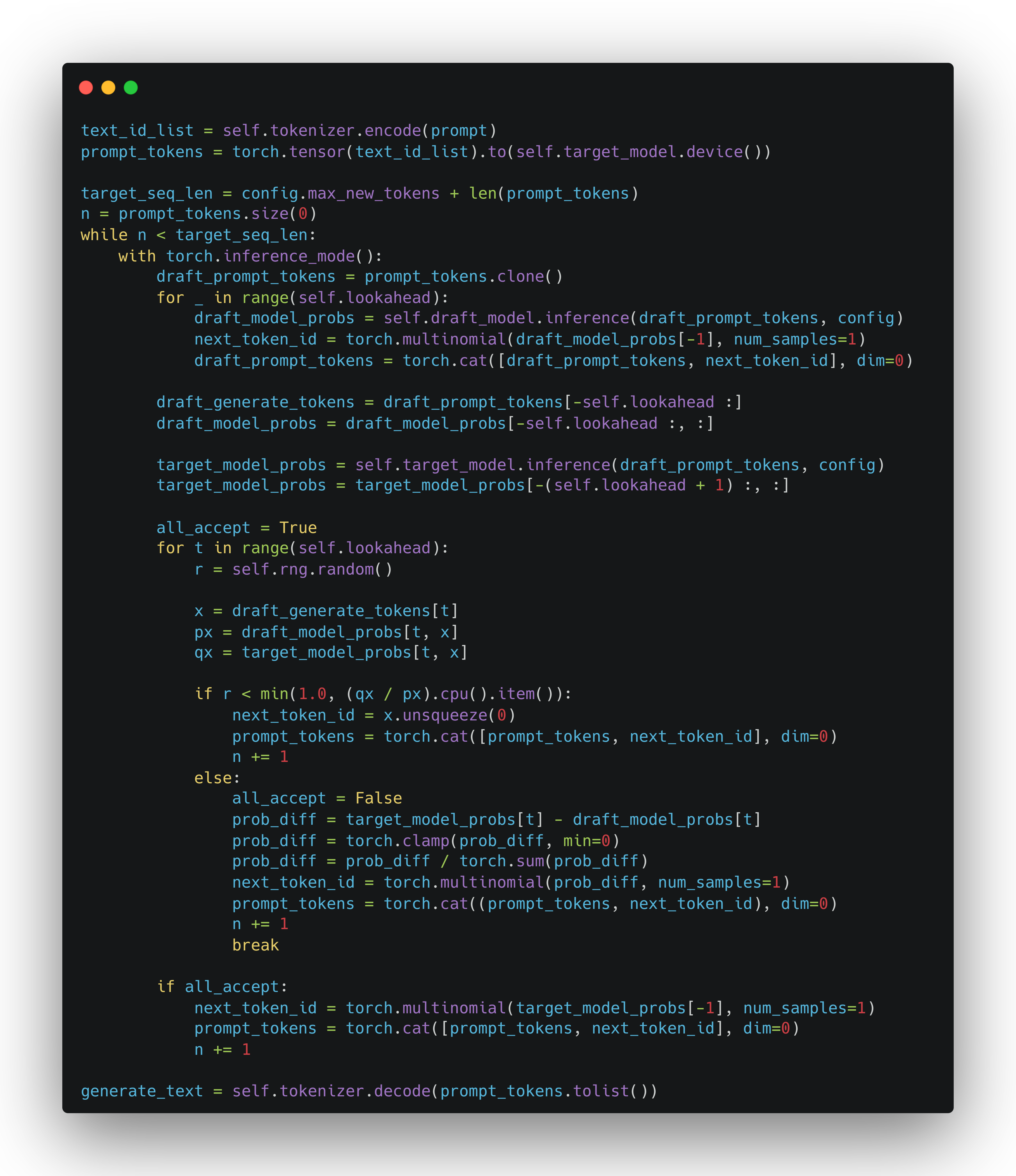
 |
1
huangyezhufeng OP 大家有疑问的地方欢迎到博客评论区交流~
|