
[开源]ACG2Vec——ACG 相关深度学习应用(以图搜图、插画评分、文本搜图等)
OysterQAQ · OysterQAQ · 2023-07-25 19:41:44 +08:00 · 6939 次点击这是一个创建于 505 天前的主题,其中的信息可能已经有所发展或是发生改变。
ACG2vec全称为Anime Comics Games to vector 。本 repo 会持续维护一些基于二次元相关的深度学习领域实践与探索。
在线预览(目前包含文本搜索、以图搜图、文本搜图、图片分数预测):https://cheerfun.dev/acg2vec/
开源仓库:https://github.com/OysterQAQ/ACG2vec
演示页前端开源仓库:https://github.com/wewewe131/acg2vec-frontend
以上两个仓库求个 star QAQ🌟🌟🌟
目前模块包括:
-
model:深度神经网络模型模块,目前包括
-
acgvoc2vec:基于从维基百科动漫列表、萌娘百科、Bangumi 、pixiv 、AnimeList 等来源获取清洗处理抽取的 510w 语句对微调的 sentence-transformers 模型,生成二次元相关文本的特征向量,用于各种下游任务(标签推荐,标签搜索,推荐系统等)
可以使用 Huggingface 在线体验:https://huggingface.co/OysterQAQ/ACGVoc2vec
-
dclip:使用 danburoo2021 数据集对 clip ( ViT-L/14 )模型进行微调。
可以使用 Huggingface 在线体验:https://huggingface.co/OysterQAQ/DanbooruCLIP
-
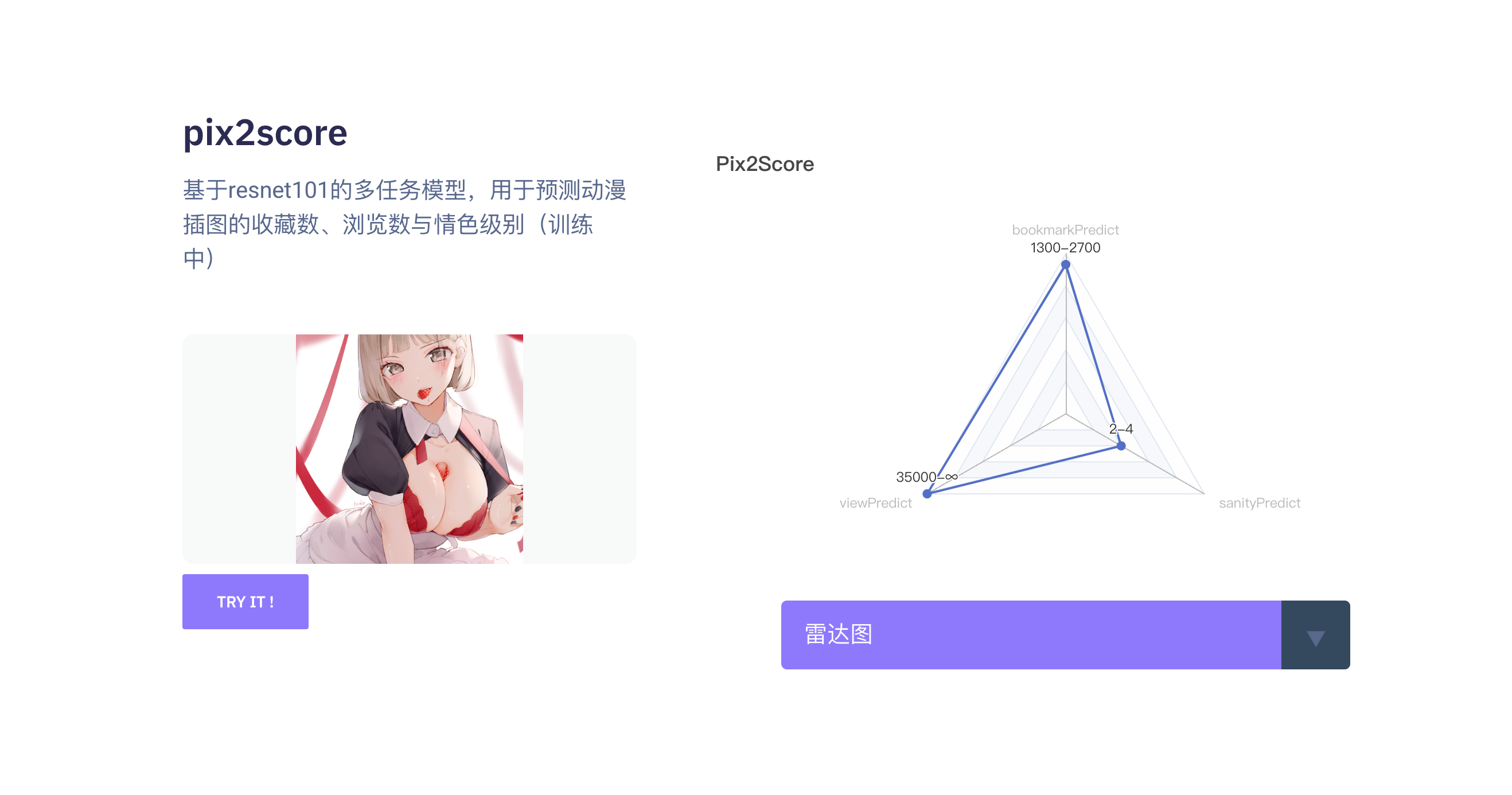
pix2score:基于 resnet101 的多任务模型,用于预测动漫插图的收藏数、浏览数与琴瑟级别
-
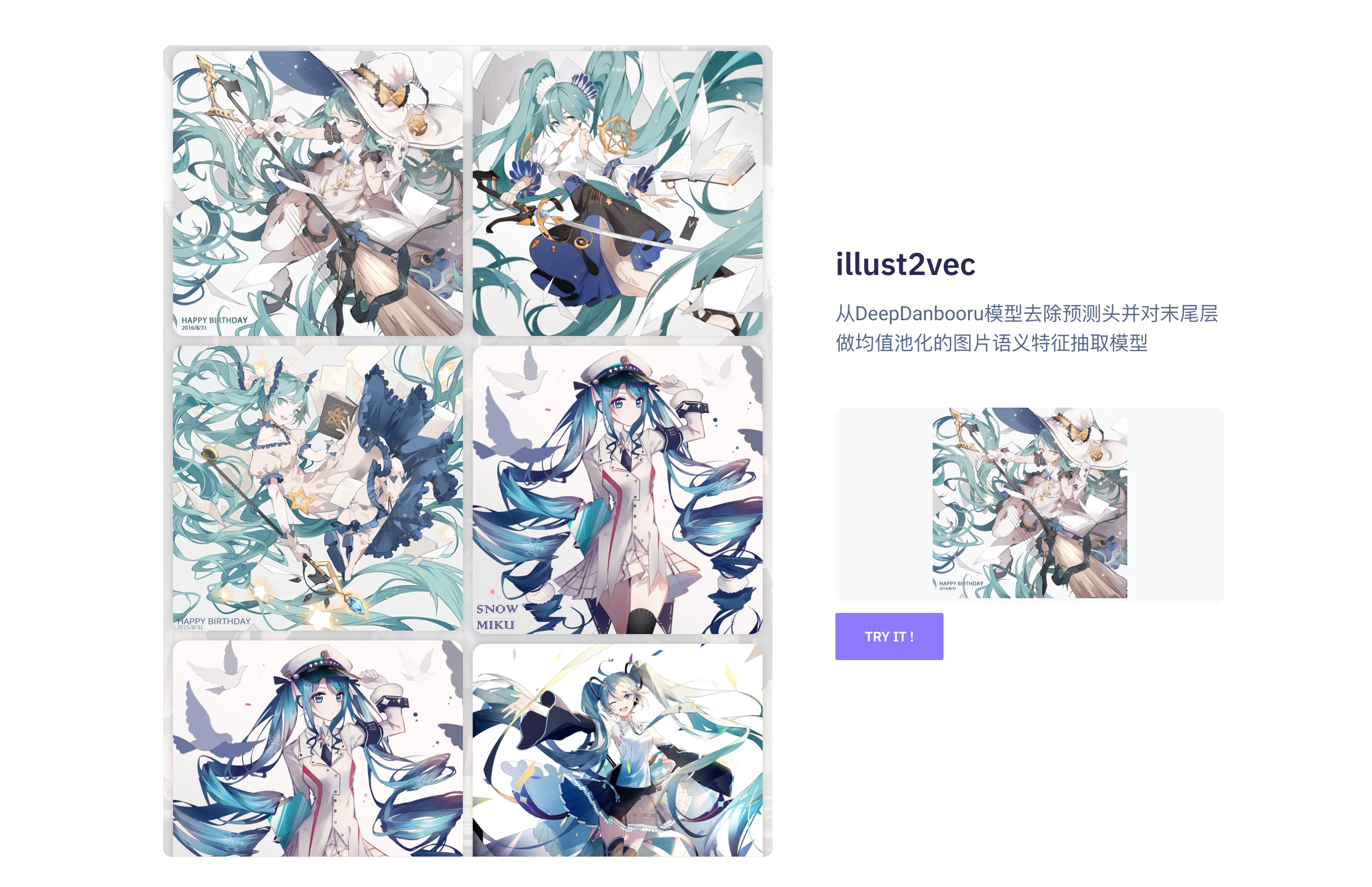
illust2vec:从DeepDanbooru模型去除预测头并对末尾层做均值池化的图片语义特征抽取模型
-
-
webapp:对外提供 web 服务模块。目前包括开箱即用的二次元插画标签预测服务、以图搜图服务、插画特征抽取服务、文本特征抽取服务
-
docker:基于容器化的部署模块,包括了部署所需要的配置文件与资源文件
💡预览
语义文本搜索

语义图像搜索
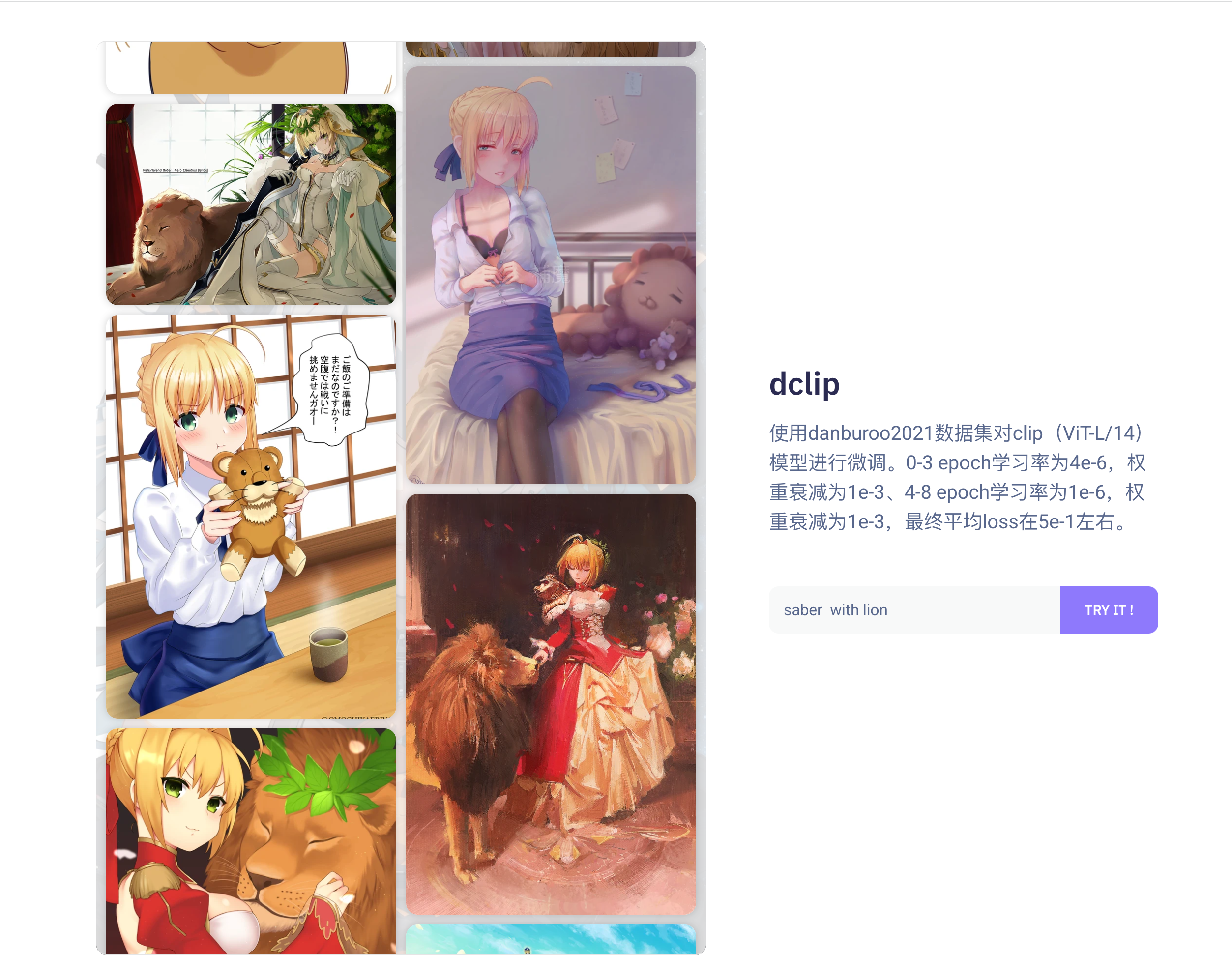
插画综合评分预测
以图搜图
 |
1
zoharSoul 2023-07-25 20:46:24 +08:00
大佬 nb!!!
|
 |
3
tanranran 2023-07-26 12:53:27 +08:00
研一就这么强了,大佬牛批
|
 |
6
OysterQAQ OP @tanranran 不考虑读博了,现在深度学习应用科研消耗不是一般人能承受的了,而且更喜欢工业界的一些东西(实用,有意义),学术界上缝合的太多了(包括我自己)。而且硕士运气好老师挺不错的,也见到很多其他的老师,读博还得再 roll 一次🐶
|
 |
7
Aloento 2023-07-26 16:18:47 +08:00
太强了,愿意贡献一张 A100 给大佬助助兴
|
|
8
OysterQAQ OP @Aloento 感谢大佬,不过目前没啥需求了,也没想到什么合适的新项目。以上项目主要是数据集都很大 需要本地存储,我自己组的 3080+3090 ,本地机械 80t ,有很大一部分都被数据集占了(特别是为了训练时候不预处理,提前存储好二进制的已经预处理好的数据集文件)
|
 |
9
LancerComet 2023-07-26 18:47:08 +08:00
acgvoc2vec 有点意思,我给自己做了一套收图的图库跑在了群晖上,图片有 tag 和 tag 同义词,不过同义词都是手动关联的,acgvoc2vec 可以做到自动化;另外 dclip 是不是也可以反着来,通过图片生成 tag
|
|
10
OysterQAQ OP @LancerComet dclip 通过图片生成 tag 可以用向量检索方式实现,不过类似 BLIP 这种生成式可能更好一些
|
 |
11
xiaoxiao168 2023-07-27 10:24:40 +08:00
@OysterQAQ 有考虑像 生成 模特儿吗? 有些公司在搞了, 更新不同产品 ,目标消费者 生成不同的模特,这个算“工业界”吗? 不是很懂,
(有兴趣做(跨境)电商的朋友 欢迎交流 https://discord.gg/VjWJbTjNWQ 跨境电商 合作共赢) |


|
14
LancerComet 2023-07-27 17:58:37 +08:00
@OysterQAQ
简单试了一下 acgvoc2vec 还行,给自己的小图库晒同义词合并是够了,随便试了一下: The similarity between '赤井心' and '赤井はあと' is 0.7822584509849548 The similarity between '虚拟主播' and 'VTB' is 0.5672250986099243 The similarity between '虚拟主播' and 'VTuber' is 0.5994329452514648 The similarity between 'VTuber' and 'VTB' is 0.7549457550048828 The similarity between 'JK' and '高中女生' is 0.6553347706794739 The similarity between 'Maid' and '女仆' is 0.7300522327423096 不过还没想好怎么集成,目前只想到做成选择某个标签的时候将评分高的同义词都列出来然后自己筛选,平时只需要往里填同义词之后再筛选就可以,感谢楼主开源 PS:果然最宝贵的还是数据,只看到一条数据库 connect string |
|
15
OysterQAQ OP @LancerComet 统计科学是这样的,数据是基础😬
|
 |
16
wentx 2023-07-28 10:55:31 +08:00
啥时候可以以图搜片?
|
 |
18
charslee013 2023-07-28 18:05:33 +08:00
赞美大佬开源~
有个问题想请教一下,我自己搭建试了一下,发现 web-app 里面没有 `/similarityImages` 路由 这是要自己搭建一个向量库存储全部图片的特征,然后根据上传图片的特征值(阈值为 0.5)来做匹配么 🤨 |
|
19
OysterQAQ OP @charslee013 yes 本来有打算集成,但是太臃肿了,自己搭建更加自由一些。
|
|
20
OysterQAQ OP @charslee013 额 看错了 相似度搜索没有阈值的说法,是直接搜出 topk 相似的
|
 |
21
lopssh 2023-07-30 09:05:32 +08:00 via Android
谢谢分享。
|
 |
22
zzzlight 2023-08-01 09:40:48 +08:00
厉害的,虽然我研究生是做向量搜索的,曾经也有过做这个的想法,可惜行动力不足+实验室折磨导致彻底被恶心到了。楼主研一虽然都是开源库,把这一套搞出来真的很不容易了。
|
|
23
OysterQAQ OP @zzzlight 感谢认可🙏,没有啥模型创新能力,喜欢用受得住工业界检验的,例如分类模型用 ResNet 而不去魔改 vit 之类的。可能代码上有帮助的就是一些模型应用经验,例如大的生产数据集如何去训练,以及大数据集训练过程出现的问题解决🥳。
|
|
24
zzzlight 2023-08-01 09:53:40 +08:00
这玩意核心还是数据,我还记得以前实验室师弟高强度爬数据的日子 5555555555 。以及被硬盘爆满支配的恐惧。
|
|
25
zzzlight 2023-08-01 09:54:51 +08:00
@OysterQAQ resnet 够用了(这方面真的越经典的越好用,确实是有原因的,很多灌水的或者好像很火的论文在工业应用上是大粪)
|
|
26
zzzlight 2023-08-01 10:02:05 +08:00
检索上 milvus 的集成了不少算法,可以都试试(最后会发现还是经典的 HNSW 最好用)。工业上主流还是 ivfpq 、HNSW 这些,milvus 好像把 diskann 这种超大规模的集成了,但是还是不如经典的 HNSW (听说 milvus 最近魔改进 Diskann 了)。反正检索方面是这个情况。
|
|
27
OysterQAQ OP @zzzlight #26 我现在近似度量用的是预先 L2+dot ( milvus 文档示例也是这种方式)来等效 Cos Similarity 的方式,milvus 默认聚类索引好像是 faiss ,没有比较过 faiss 和 ann 的差别
|
|
28
zzzlight 2023-08-01 10:11:37 +08:00 @OysterQAQ faiss 是 Facebook 的一个库,里面有常见的一些算法比如 pq 、ivfpq 、HNSW 这些,ann 是近似最近邻搜索的意思(现在换了个皮叫向量检索),faiss 是 ann 的搜索算法库。是这么个关系。
|
|
29
zzzlight 2023-08-01 10:15:03 +08:00 除了用 faiss 的话,没事你可以看看 milvus 的配置,换换别的方法,底层用基于图的一些算法或者聚类量化+图结合的应该能提高不少检索精度(不过这个也看你数据量,上亿如果一亿数据还能勉强用用图,更多就只能 pq 算法(又叫基于量化的算法)或者他们的魔改版 diskann 了)。
|
|
31
zzzlight 2023-08-01 10:16:43 +08:00
检索上就是速度和精度的权衡,根据你的数据量、内存大小的取舍。
|
|
32
zzzlight 2023-08-01 10:18:24 +08:00
向量检索是个大坑,发论文啥的就别碰这个了,对 c++实力要求太高了,而且很多现在的论文也是想尽办法水(属于水都不好水了)
|
|
33
zzzlight 2023-08-01 10:20:22 +08:00
不过 milvus 上那些已经算是能用的算法可以都了解一下,就那么几篇论文,应该对你提高搜索精度上能有所帮助。名字就是我上面提到的一些,考虑到你主要估计是做学习的,省事可以直接看知乎,勤快点就看看论文原文。
|
|
35
zzzlight 2023-08-01 10:27:13 +08:00 解释一下为啥 milvus 里面有 faiss ,因为所谓的 milvus 核心的代码还是从 faiss 的开源库里面拿过来魔改的,反正现在就是啥开源啥拿来魔改缝合,我不知道你是用的哪个语言接口,里面提供的方法还有哪些,但是这个玩意核心还是用 c++实现的,提供的 mode 溯源的核心算法应该就是那几个(抱歉好久没看 milvus 的调用接口了,现在也不记得了)。
|
|
36
LancerComet 2023-08-03 00:57:38 +08:00
@zzzlight 您好打扰了,想向您请教一下,我现在准备更新图库的相似图片搜索功能,之前用的是图片哈希这种传统方式,现在打算用 pgvector 直接在 postgres 上存储并索引 Resnet 152 的特征来实现这个功能,查询就打算直接用 pgvector 提供的 L2 distance 方法,非常简陋的一套,不知道您是否能评估类似这样的方案一般能应对多大的数据量的查询
|
|
37
zzzlight 2023-08-03 10:09:46 +08:00 @LancerComet 你好,我稍微看了下 pgvector 的 git ,好像他们提供的 l2 距离的搜索是直接用的 faiss 的 ivfflat 方法(也就是是聚类大致分几个桶之后查询点和图库中数据暴力遍历的思路)(也叫倒排索引)。具体的 pgvector 的表现情况可以看: https://ann-benchmarks.com/pgvector.html 这里用常用的一些数据集(基本就是手写数字和一些经典图像转换过来的究极经典数据集)评估了 qps 情况,查询量可以参考这个的 qps ,理论上来说这些数据集都是被算法极大适应的数据类型,真实世界的查询情况只会差不会好(单由于你这个本来也就是暴力遍历,我估计会和真实环境下差不多)。大致达到 90 多的召回率在 10-100 的 qps 这个范围。
|
|
38
LancerComet 2023-08-03 12:15:06 +08:00
@zzzlight 非常感谢您的指点,我去看看
|
 |
39
GoRoad 2023-08-05 14:32:07 +08:00
还记得当年认识你的时候 买你自己搭的服务 现在都这么强了
|
 |
41
fengxiangwan 2023-08-06 00:17:43 +08:00
生蚝!
|
|
42
OysterQAQ OP @fengxiangwan 大佬是哪位👀
|